FWF P19939-N13: "Compiler Technology for Top-Performance Signal Transforms"
General Overview
This page presents
the FWF
stand-alone project P19939-N13 "Compiler Technology for
Top-Performance Signal Transforms", which was carried out by
Stefan Kral between August 2007 and February 2011.
Project funding was
provided by Austria's central funding organization for
basic research,
the Austrian Science
Fund ("Fonds zur Förderung der wissenschaftlichen Forschung",
FWF).
This project focused on the development of compilation
techniques for speeding up top-performance signal transform
codes running on Intel64/AMD64 processors. All compilation and
optimization techniques were implemented in NXyn (pronounced
"neck-sin"), a synergistic compiler for Intel64/AMD64 processors.
The NXyn compiler comprises two main components:
- nxas: a assembly-level source-to-source code optimizer which aims at reducing code size and run time.
- nxcc: a C compiler driver, which can be used as a drop-in replacement of GNU C or Intel C compiler.
nxcc uses another C compiler for generating assembly code, which it passes on to nxas for post-processing.
This structure allows NXyn to process hand-written assembly code
and to cooperate with proprietary, closed-source compilers like the
state-of-the-art Intel C compiler.
To cooperate with existing compiler technology and state-of-the-art
signal transform libraries in the best way, NXyn focuses on compiler
backend optimizations. Its optimization methods are fully orthogonal
to established optimization techniques present in modern C
compilers. In particular, NXyn features:
- Address code optimization which is tailored to signal
transform access patterns. For large codes, this optimization reduces the address instruction count
by more than 80%.
- Stack offset assignment which reduces code size by up to 10%.
- SIMD vector register reassignment which, in many cases, reduces code size by more than 5%.
Target Platforms
NXyn is exclusively available for Intel64/AMD64 processors
running the GNU/Linux operating system in 64-bit mode.
Processors based on the following micro-architectures were used during for development and testing:
- Intel Core: Intel Core 2 "Conroe"/"Merom", Intel Core i3 "Arrandale".
- AMD K10: AMD Phenom "Barcelona", AMD Phenom II "Shanghai".
In addition to these processors, NXyn is likely to be useful for other Intel64/AMD64 processors, including
Intel Core i5 "Clarkdale", Intel Core i7 "Nehalem", Intel Atom, and VIA Nano "Isaiah".
Target Codes
Code optimizations implemented in NXyn particularly benefit program
codes comprising long basic blocks.
NXyn works both with scalar code and
SIMD code (Intel SSE, Intel SSE2, Intel SSE3, Intel SSSE3, AMD SSE4a, Intel SSE4.1, and Intel SSE4.2), equally supporting integer and
floating-point calculations.
Performance Results
Compiling the widely used discrete Fourier transform
library FFTW with NXyn (in
combination with the Intel C compiler version 11.1)
consistently minimizes both run time and code size.
The following performance diagrams show that NXyn consistently
improves the performance of FFTW routines running on Intel64 and AMD64
processors. All measurements have been performed using a single
processor core.
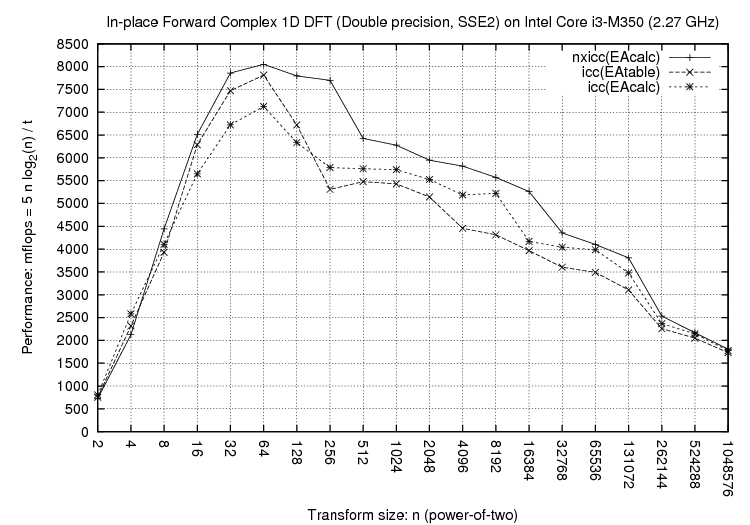
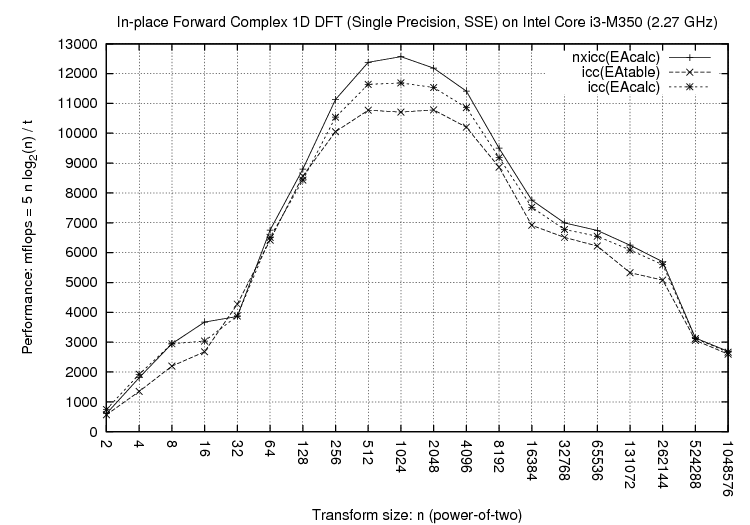
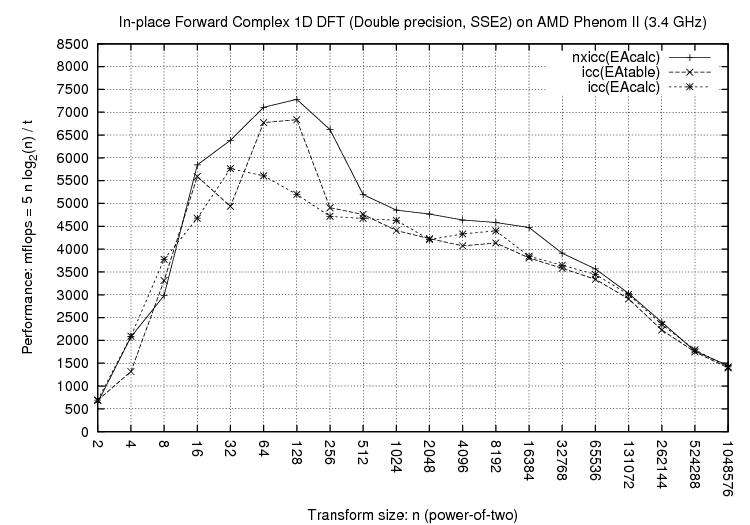
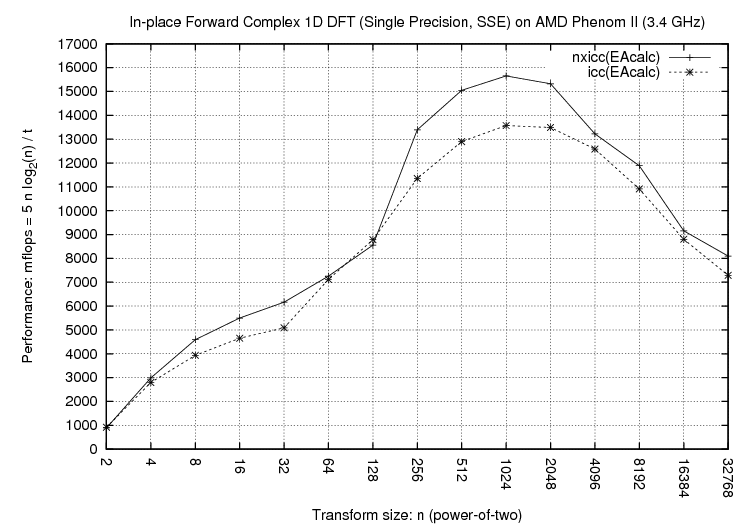
Above plots compare three configurations:
- icc(EAcalc): Intel C compiler with maximum optimizations
- icc(EAtable): As above, but with the FFTW library code caching address calculations in a table, which works around a limitation present in most compilers for Intel64/AMD64 processors.
- nxicc(EAcalc): Intel C compiler with maximum optimizations plus NXyn optimizations
As the performance plots show, NXyn gives significant performance
improvements for both Intel and AMD processors, for different problem sizes,
and for different instruction sets (SSE, SSE2). More performance plots featuring other problem sizes
and problem types are available here.
To maximize FFTW performance, consider generating a larger set of codelets than the one included in the standard FFTW distribution. Information on how to do this is available on the FFTW web page here.
Publications
The following publications are related to details of the NXyn compiler
and the signal transform specific compilation techniques that it
implements.
- BlueGene/L applications: Parallelism On a Massive Scale (2008)
- B. R. de Supinski, M. Schulz, V. V. Bulatov, W. Cabot, B. Chan, A. W. Cook, E. W. Draeger, J. N. Glosli, J. A. Greenough, K. Henderson, A. Kubota, S. Louis, B. J. Miller, M. V. Patel, T. E. Spelce, F. H. Streitz, P. L. Williams, R. K. Yates, A. Yoo, G. Almasi, G. Bhanot, A. Gara, J. A. Gunnels, M. Gupta, J. Moreira, J. Sexton, B. Walkup, C. Archer, F. Gygi, T. C. Germann, K. Kadau, P. S. Lomdahl, C. Rendleman, M. L. Welcome, W. McLendon, B. Hendrickson, F. Franchetti, S. Kral, J. Lorenz, C. W. Ueberhuber, E. Chow, and Ü. Çatalyürek.
- In the International Journal of High Performance Computing Applications, Volume 22, No. 1, Spring 2008, pages 33-51.
- Smaller and faster Intel SSE Code (2011)
- Stefan Kral
- Submitted to Euro-Par 2011 -- International Conference on Parallel and Distributed Computing.
Download
NXyn is open-source software available under the GNU General Public License (GPL), version 2.
The current version of NXyn is available here (release notes).
Information about installing NXyn is available here.
FFTW 3.2.2 pre-compiled with Intel icc and NXyn is available here (double precision) and here (single precision).
Last update: Sun Jun 26 18:44:18 CEST 2011