Garbage Collection Algorithmen - Seminar SS95
Verfahren zur Speicherrueckgabe
Martin Exler, 9126090
Es handelt sich bei diesem Dokument um eine Zusammenfassung der Kapitel
3.4 - 3.4.6 der Diplomarbeit von Ulrich Neumerkl
"3.4
Verfahren zur Speicherrueckgabe".
- Ausgangspunkt
- Nicht mehr referenzierbare Zellen sind bereits erkannt (markiert)
worden.
Der freie Platz kann daher wieder vergeben werden. Dafuer gibt es zwei
Varianten:
- Die freien Zellen werden ueber eine eigene Verwaltung direkt
fuer neue Zellen verwendet, oder
- man verlegt die referenzierbaren bzw. freien Zellen in einen
geschlossenen Bereich.
Mark and Sweep
Nach der Markierungsphase wird der Speicher durchsucht und die freien Zellen
werden in einer Freispeicherliste miteinander verkettet. Bei einer
Speicheranforderung wird in dieser Liste nach einem passenden
Speicherbereich gesucht.
Anmerkungen:
- aktive Zellen werden nicht verschoben -> Referenzen muessen
nicht aktuallisiert werden
- fluechtige Datenstrukturen fuehren zu einer schnellen
Alterung des Speichers
- der Speicher wird fragmentiert (abhaengig von
Verteilung der Lebenserwartung)
Dijkstras On-the-Fly
Vollkommene Parallelisiserung der Markierungs- und
Reorganisationsphase:
- Der mutator fuehrt die Verarbeitung und die
Speicheranforderunge
n durch,
- Der collector fuehrt die Markierung durch und haengt
unbenutzte
Zellen in einer Freispeicherliste zusammen.
Die Markierung verwendet 3 verschiedene Zustaende fuer jede
Speicherzelle:
- weisz.....unmarkiert
- schwarz...markiert
- grau......Zelle wurde vom Programm benoetigt
Der mutator unterstuetzt die Markierungsphase dadurch, dasz er
die weiszen Zellen, die er verwendet auf grau setzt. Auszerdem sendet er
dem collector ein Triggersignal, wenn die Freispeicherliste nur
mehr eine Zelle enthaelt. Der mutator musz dann solange warten,
bis der collector mindestens eine weitere Speicherzelle
verfuegbar gemacht hat.
Der collector musz die benutzten Zellen, die Zellen in der
Freispeicherliste und alle grauen Zellen markieren. Zuerst setzt er die
erste benutzte und die erste Zelle der Freispeicherliste auf grau. Dann
werden alle Zellen, die durch eine graue Zelle z referenzierbar
sind auf grau gesetzt und anschlieszend wird z auf schwarz
gesetzt.
Am Ende des Durchlaufes werden die weiszen Zellen in die
Freispeicherliste eingehaengt und danach werden die schwarzen Zellen
weisz gefaerbt. Dadurch werden inaktive graue Zellen zuerst schwarz und
dann weisz. Im naechsten Durchlauf werden diese Zellen dann in
die Freispeicherliste eingehaengt.
Anmerkungen:
- collector sollte doppelt so schnell sein, um Wartezeiten
des mutators zu vermeiden
- Freispeicherliste genauso aufwendig behandelt, wie
referenzierte Zellen
- Der Aufwand ist im wesentlichen abhaengig von der Fluechtigkeit der
Datenstrukturen, je kurzlebiger sie sind, desto schlechter ist der
Algorithmus.
Abraham & Patel
- Freispeicherlisten seitenweise aufgebaut (virtueller Speicher)
Solange der mutator auf einer Seite nichts
geaendert hat, wird fuer mutator und collector dieselbe Seite
verwendet. Beschreibt er eine Zelle der Seite, so musz fuer mutator
und collector jeweils eine eigene Repraesentation der Seite erstellt
werden, spaeter werden diese Repraesentationen wieder vereinigt.
Kompaktierende Algorithmen
- aktive Zellen in einem zusammenhaengenden, moeglichst kleinen
Bereich -> virtueller Speicher wird effizienter genutzt
- Erhaltung der Lokalitaet (wichtig fuer Cache)
- aktive Zellen werden verschoben -> alle Referenzen muessen
aktuallisiert werden
Knuths LISP2
Jede Speicherzelle enthaelt ein eigenes Feld, in dem ihre neue Adresse
steht (dieses Feld wird auch zur Markierung verwendet).
Vorgangsweise:
- entsprechend der Markierung neue Adressen fuer die Zellen
berechnen/speichern
- alle Zeiger auf die neuen Adressen aktuallisieren
- alle Elemente kopieren
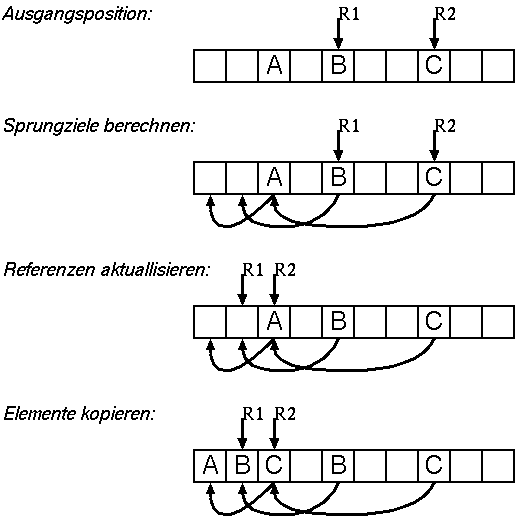
Anmerkungen:
- Speicheraufwand: ein zusaetzlicher Zeiger pro Speicherzelle
(bei Prolog: fast doppelter Speicherplatz benoetigt)
- diverse Varianten zur Beschleunigung (getrennte Verwaltung
der Markierungsbits, Zusammenlegung von Phasen,..)
Table Compactors, Haddon & Waite, Wegbreit
Es wird gleich mit dem Verschieben begonnen, die Verschiebungen werden
in einer Tabelle mitprotokolliert.
Vorgangsweise:
- Die aktiven Zellen werden einzeln verschoben, dabei wird immer ein
entsprechender Eintrag in die Tabelle eingetragen (man kann die Tabelle
"rollen" um einen benoetigten Speicherbereich benutzen zu koennen).
- Die Tabelle wird sortiert.
- Die Zeiger werden mit Hilfe der Tabelle aktuallisiert

Table-Compactor w�hrend Phase I
Anmerkungen:
- die Reihenfolge der aktiven Zellen im Speicher bleibt
erhalten
- die kleinstmoegliche Zelle musz mindestens einen Tabelleneintrag
enthalten koennen
- Aufwand: n log n
- n...Anzahl der referenzierten Zellen, oder
- n...Groesze des gesamten Speicherbereichs)
- viele Heuristiken anwendbar
Edwards Kompaktierer
Vorgangsweise:
- Es werden 2 Zeiger verwendet, mit dem einem sucht man freie Zellen,
mit dem anderen (in entgegengesetzter Richtung) nach markierte Zellen. Die
markierten Zellen werden in die freien Zellen kopiert, in der alten Zelle
wird ein Zeiger auf die neue Position gespeichert. Treffen sich die
beiden Zeiger, so ist man fertig.
- Suche die Zeiger, die auf verschobene Zellen zeigen und
aktuallisiere sie.
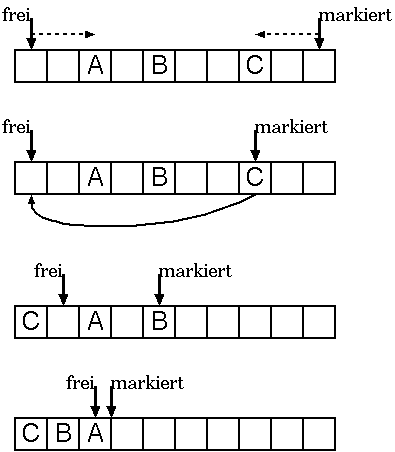
Anmerkungen:
- die Reihenfolge der Zellen wird nicht erhalten
Kopieralgorithmen
Kopieralgorithmen kombinieren Markierung und Kopieren der Zellen in einer
Phase. Nach dem vollstaendigen Durchlauf befinden sich alle aktiven Zellen
in einem durchgehenden Block. Der restliche Speicher ist frei.
Anmerkungen:
- Fragmentierung wird vermieden
- Lokalitaet der Referenzen wird erhalten
- wesentlich bessere Laufzeit als mark-scan Algorithmen
(abhaengig von der Anzahl der aktiven Zellen)
- effiziente Verwaltung fluechtiger Datenstrukturen
- permanente Datenstrukturen: Aufwand proportional zur
Lebensdauer der Daten
Minsky
Fuer alle aktiven Zellen wird jeweils ein Tripel (zukuenftige Position
der Zelle, rechter und linker Zeiger) berechnet und in einer Datei
gespeichert. Die neue Adresse wird auszerdem in der markierten Zelle
gespeichert. Nach der Kompaktierung stehen Zellen die miteinander
verbunden sind im Hauptspeicher nahe beisammen.
Fenichel-Jochelson - Twospace Kompaktierung
Der Speicher wird in zwei gleich grosze Bereiche A und B aufgeteilt.
Zuerst werden alle Speicherelemente in A angelegt. Ist hier der Platz
erschoepft, so kopiert man die Zellen nach B. In A wird ein Verweis auf
die neue Position abgespeichert. Trifft man beim Kopieren auf einen
solchen Verweis, so verwendet man diesen als Wert. Anschlieszend wird
B zum aktiven Bereich.
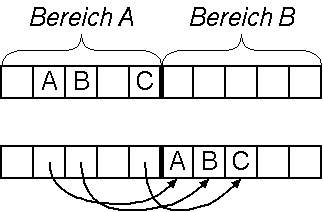
- kein eigenes Markierungsbit notwendig (Adreszvergleich)
- rekursiver Algorithmus zum Durchwandern der Zellstruktur
verwendet
Scavening Algorithms
Bakers Kopieralgorithmus
Der Speicher wird in zwei gleich grosze Bereiche aufgeteilt. Es werden
aber nicht alle Zellen auf einmal in den neuen Bereich kopiert, sondern
zuerst nur eine fixe Anzahl von Elementen. Im Zuge der weiteren Ausfuehrung
des Programmes wird nun:
- beim Anlegen einer neuen Zelle eine konstante Anzahl von Elementen
mitkopiert
- beim Zugriff auf eine Zelle sicherergestellt, dasz sie sich im neuen
Speicherbereich befindet (wenn noetig wird sie kopiert).
- die Zellen im neuen Bereich werden nach alten Referenzen
durchsucht, die referenzierten Zellen werden in den neuen Bereich
kopiert; durch Wiederholung dieses Schrittes erhaelt man eine
Breitensuche
Anmerkungen:
- Programm verhaelt sich so als ob sofort nach dem Aufruf der
Speicherbereinigung alle Zellen kopiert worden waeren
- kein Stack notwendig
Ringkompaktierung
Hier wird nicht zwischen zwei abgegrenzten Bereichen hin- und
herkopiert, sondern der Speicher wird als Ringspeicher angesehen. Der
aktive Bereich durchwandert den Speicher, auf der einen Seite werden
neue Elemente angelegt, auf der anderen Seite laeszt man nur freie
Zellen zurueck. D.h. mueszte man eine aktive Zelle zuruecklassen, so
wird sie an den Anfang des aktiven Bereiches kopiert.

MALI's Ringkompaktierer
- aehnliches Verhalten wie Twospace-Kompaktierung
Liebermann und Hewitt
Der Speicher wird in viele kleinere Bereiche aufgeteilt. Dadurch ist es
moeglich sowohl kurzlebige als auch permanente Datenstrukturen
effizient zu verwalten.
Jeder Speicherbereich enthaelt eine Generations- und Versionsnummer. Da
in LISP fast nur Zeiger von juengeren Zellen auf aeltere Zellen
erzeugt werden, koennen juengere Generationen unabhaengig von aelteren
behandelt werden.
Dieses Verfahren eignet sich auch besonders fuer Prolog, da es keinen
Mehraufwand zur Laufzeit benoetigt - die Generationen werden hier schon
von der Semantik der Sprache benoetigt.
Ungar generation scavenging
Dieses Verfahren wurde im Hinblick auf Smalltalk entwickelt. Es geht
auch auf die typische Lebenserwartung der Zellen ein.
- Jede Zelle wird entweder mit alt oder mit neu klassifiziert.
- Alte Zellen befinden sich in einem eigenen Gebiet, ihre
Referenzierbarkeit wird eher selten geprueft.
- Alte Zellen, die auf neue Zellen verweisen, gehoeren einer eigenen
Menge an (remembered set).
- Alle erreichbaren neuen Zellen muessen ueber dieses remembered set
erreichbar sein.
Die neuen Zellen werden in 3 verschiedene Bereiche unterteilt:
- New Space zur Allokierung neuer Zellen
- PastSurvivorSpace Zellen, die bereits eine Bereinigung hinter
sich haben
- FutureSurvivorSpace wird das Ziel des naechsten Kopierens
Vorgangsweise:
- Die erreichbaren Zellen aus NewSpace und PastSurvivorSpace werden in
den FutureSurvivorSpace kopiert.
- Past- und FutureSurvivorSpace werden vertauscht.
- Ist eine Zelle lange genug neu, dann wird sie alt (und in den
entsprechenden Bereich kopiert).
Anmerkungen:
- die meisten Smalltalksysteme basieren auf diesem Algorithmus
- Beschleunigung durch: Sonderbehandlung von bitmaps und strings,
adaptive Varianten
/usr/gtp/pub/ulrich/gc

