Markus Schordan, TU Wien
Abstraction is an important concept to be aware of and use appropriately. I believe raising the level of abstraction is fundamental in all practical intellectual endeavors. But in software development a higher level of abstraction usually gives less efficient programs. This is true for high-level languages as well as for high-level interfaces in libraries. My approach to this reciprocal problem of abstraction and performance shows, that if both are addressed, I can also address correctness and verification.
Supporting the design and creation of multiple levels of abstraction is paramount in the development of today's software. Higher level abstractions can only be built on trusted lower-level abstractions, which may be represented by a combination of components, services, and collections of other abstractions. But abstraction without the required performance is not used, not accepted by a reasonable large user-base, and not useful for any real-world application. To go beyond testing, additional information about user-defined abstractions must be specified by users and verified by the compiler. This combined approach permits creating high quality software systems.
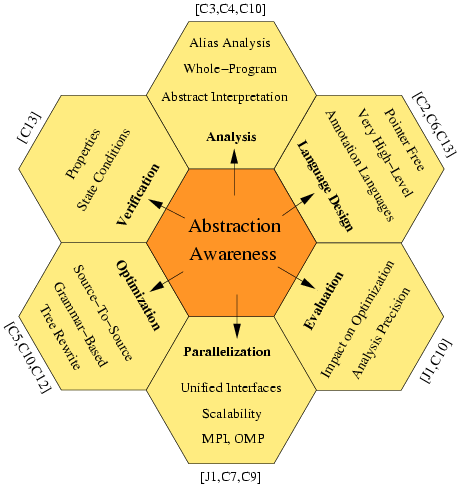
To achieve that goal my research has six major directions with abstraction awareness at its center, as shown in Fig. 1. The program analysis is made abstraction aware by using additional semantic information that is provided via annotations of the program. The optimization and parallelization of a program is abstraction aware if it can utilize the results of an abstraction aware analysis. The annotations must be powerful enough to permit the concise specification of high-level properties of a program. This requires language design for annotation languages. The correctness of the annotations, which specify properties of a program, can be verified by precise analysis and proving techniques to some extent, also known as partial verification. The evaluation, in particular of real-world applications, is essential to gain insight into the relevance of abstraction-aware optimizations compared to traditional optimizations.
My work at the Lawrence Livermore National Laboratory on domain specific optimizations and the continued work in the field of high-performance computing shows that it is indeed possible to eliminate the performance penalty if high-level semantics can be utilized in optimizing the use of high-level abstractions. It is possible to achieve similar performance as with low-level High Performance Fortran code. The basic idea is to provide enough information through annotations such that user-defined types can be treated like built-in types. The opportunity of directly influencing the performance of the generated code is a good motivation for developers for specifying properties of their programs by writing annotations - this is a better motivation than promising correctness only. Once the annotations are there, I can focus on precise analysis and verify the correctness of the annotations.
This way the developer is rewarded for providing additional semantic information with high performance and verification. Abstraction, performance, and correctness must be understood and presented to developers such that they can see their direct influence on all three of those essential aspects of computing.
In the next sections I explain in more detail what my contributions have been in each of the directions and how they contribute towards the general goal of abstraction awareness in optimizing compilers.
Abstraction awareness is important because it permits performing transformations on programs that could not be performed based on traditional conservative analysis. Additional semantic information is provided via annotations, and this additional knowledge is utilized in analysis and transformation. By using this additional high-level information the performance penalty of high-level abstractions can be eliminated.
If an analysis uses the additional semantic information provided via annotations of an abstraction, it is an abstraction aware analysis. In [C10] I contributed an analysis that uses the high-level semantics of an array abstraction, allowing the optimization of a group of array operators. The analysis combines the high-level information provided via annotations with data flow analysis. Most relevant to me is precise analysis that permits establishing non-trivial properties of programs, such as shape analysis for heap allocated data structures, and dependence analysis for array optimizations. My contributions in the field of alias analysis is the development of analysis methods for precise analysis of inter-procedural shape analysis with multiple summary nodes [C4,C3] and the integration of aliasing properties provided via annotations.
Once I have annotations in a program, I can verify whether these annotations are correct with precise program analysis. By that approach I am able to verify the specified properties. When writing a specification it is difficult to decide in advance what is a good level of abstraction. This matter is simplified when having a concrete application of that specification in mind. Therefore I am focusing on partial verification that does not check the full correctness of the program, meaning not the algorithm, but verifies that the program satisfies certain relevant properties. This lightweight approach to software verification has many advantages. It can be done incrementally, and users can achieve some progress after each such step. It allows to address refinement of performance, specification, and abstraction at the same time - and by doing so provides opportunities for insight to the user how each of those three dimensions impacts the development of the software. In [C13] I contributed a classification of optimizations by using four key properties. Each of the classes is then represented by a set of annotations that is used for specifying properties of abstractions. Some of these annotations can be generated by traditional analysis which permits verifying the existing annotations.
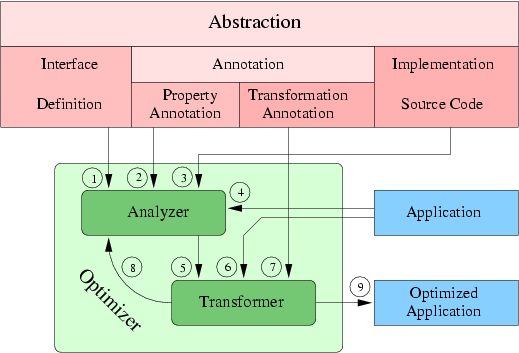
A transformation that uses the results of an abstraction aware analysis is an abstraction aware transformation. This permits extending traditional optimizations to high-level abstractions by providing the required properties for user-defined operators and data types. In [J1] I contributed the optimization of applications that use the A++/P++ libraries, which were developed at LLNL. Both libraries implement a number of different array operators. Loop optimizations can be applied to the implementation of the operators because the annotations provide the additional information that their implementations do not have side-effects on the objects on which they are performed, the type of domain on which the loops perform, and whether they change the state of the object on which they are performed. In Fig. 2 we see that the Interface Definition (1), the Property Annotation (2), the Implementation Source Code (3), and the Application (4) are input to the analyzer. This permits combining the high-level information from annotations with traditional source code analysis. The application that uses the abstraction, is analyzed by utilizing the information obtained from both the annotations and the source code analysis.
With Transformation Annotations, which are a direct input to the Transformer (7), the user can directly specify transformations that are to be applied. A well-known example is the ``inline'' directive. A more advanced application is explicitly specified loop fusion. In [C5,C10] I contributed methods for specifying transformations for abstraction aware optimization. The optimizations performed are loop optimizations that are based on annotations of different abstractions. The abstractions are (index) range and array abstractions. The range abstraction is used as indexing range for array operations and for specifying arbitrary stencil operations on arrays. The optimizations permit speeding up the investigated kernels by a factor of 3.4 to 15.2; the range in speedups stems from applying the optimization to different array sizes from 50 to 200 for 1D, 2D, and 3D kernels. The speedups are most impressive for 1D kernels, and go down to a factor of 3.4 for small 3D arrays and a factor of 5.3 for large 3D arrays of sizeMy approach to the specification of transformations is based on attribute grammars and tree rewriting, combined with using source strings in specifications. Source strings are most useful when additional code needs to be inserted into a program, such as patterns, or parameterized fragments. I have been working on the ROSE infrastructure for source-to-source transformation of C++ since 2001 [C8] and contributed a method for using abstract attribute grammars with source strings to compute sequences of transformation operations on abstract syntax trees to provide convincing examples on how short and comprehensive high-level transformations can be specified [C12].
Basis for many optimizations and insights was the optimization of applications using the A++ and P++ array libraries. Both provide the same interface, but A++ has a serial implementation whereas P++ has a parallel MPI implementation. This permits serial applications to be developed using A++ (serial arrays) and then recompiled to run in distributed memory mode using P++ (parallel arrays).
Since the parallel array semantics of A++ (and P++) are consistent with those of OpenMP, OpenMP directives can safely introduce shared memory parallelism into all uses of A++ objects. This was essential for the automated introduction of OpenMP directives without complex dependence analysis of the serial application code [C7]. Hence, it was possible to parallelize A++ code by introducing OpenMP directives for shared memory architectures.
In [C9] I generalized this concept to the parallelization of loops that iterate on user-defined containers which have interfaces similar to the list, vector and set abstraction in the Standard Template Library (STL). By providing an interface to the programmer for classifying the semantics of the abstractions, I am able to automatically parallelize operations on containers, such as linked-lists, without resorting to complex loop dependence analysis techniques. In [J1] I demonstrated that I can achieve scalable performance as with High Performance Fortran for A++ and P++ applications, which is discussed in more detail in the evaluation section.
My language development focuses on very high-level languages and annotation languages. A very high-level language permits reasoning at the level we think about a problem. My emphasis is on a language that permits specifying properties of abstractions. The initial motivation is based on C.A.R. Hoare's proposed challenge of a verifying compiler. The development of my high-level languages goes hand in hand with the development of annotation languages.
An annotation language permits a user to provide additional condensed high-level information about what his program is ``supposed'' to compute, or, in particular for embedded systems and programming hardware, which special behaviour of external resources must be considered in the optimization phase of the compiler. For example, in the optimization of applications using the libraries A++ and P++ the annotations specify semantic properties of operators implemented in the library. The operators perform operations on arrays. Each operator is implemented by iterating over multi-dimensional arrays. The annotations specify those aspects of the operators that are relevant to loop optimizations such that loop optimizations can be applied. The correspondence of the parallel P++ library and (the optimization of) a domain-specific language is discussed in [C6]. How an extension of Java with unordered sets permits the optimization of data access patterns like database queries can be found in [C2]. In this case the high-level semantics were provided by the set abstraction which allowed an optimization similar to that of data base queries. In [C13] I contribute a more general approach for annotating abstractions that contain methods for operating on containers and arrays. It is presented together with a classification of optimizations that can utilize this additional information.
The challenge in evaluating the impact of my approach is that I must measure the performance penalty introduced by a higher level of abstraction, by comparing it with another (possibly totally different) efficient implementation. Only improving the performance of some high-level constructs would not say much about the total penalty and how far we are off from the performance that can be achieved with reasonable effort. In [J1] I contributed results that clearly show that I can achieve the same performance with high-level object-oriented code and its automatic optimization compared to a High Performance Fortran implementation. The comparison was performed on a numerical solution of a linear convection equation, which was implemented using both approaches.
In Fig. 3 we can see that the penalty for the evaluated A++ application is a factor of 3.6 (dotted line compared to dashed line), and for the higher-level library P++ it is a factor of 8.8 (dot and dash line compared to dashed line). Both were compared with the available High Performance Fortran implementation (dashed line). The experiment was performed on 1 to 64 processors on the ASCI Blue Pacific at LLNL, with each node containing four 332MHz. PowerPC 604e CPUs with 1.5 GB of RAM. Because the optimization gives linear scaling, the penalty stays the same for 1 to 64 processors. For both applications I was able to eliminate the performance penalty and achieve the same performance (solid line) as with High Performance Fortran (dashed line). For this evaluation the execution time for 1 to 64 processors was investigated and a linear scaling was achieved. The array was of fixed size. The use of the A++ library required that the user code was written using MPI. An application using the P++ library was free of MPI code, the MPI calls were hidden behind the P++ library interface. Therefore an A++ application can be considered to be lower level than a P++ application. This is also reflected in the different penalties by a factor of 3.6 and 8.8. In both cases the operators implemented in the library were optimized dependent on their use in the application.
Another evaluation can be found in [C10]. It was performed with different sizes of arrays and the eliminated performance penalty was found to range from 3.4 to 15.2. The kernels represented red-black relaxation and interpolation for grid computations.
My results show that the performance penalty of high-level abstractions can be eliminated, if the high-level semantics of an abstraction can be utilized. This means that I can achieve similar performance as with low-level languages. The crucial insight from my work is that we definitely need the additional semantic information of high-level abstractions to eliminate the performance penalty.
Only if performance is addressed together with abstraction, and additional semantic information is provided, which can also be used for verification, only then we can achieve high performance and correctness when using high-level abstractions. Only then we will get close to working at the abstraction level at which we can think. In future it will become less tolerable letting people build software systems with low-level languages. Modelling will gain importance, in particular for parallel systems, as most of all systems will be parallel systems in future. But the code generated by modelling tools must include all high-level information. Techniques that are aware of that high-level semantics and can utilize that information for optimizing the code for specific platforms, are essential for achieving high performance. And only if that optimized code provides the required performance, only then users will accept such high-level tools - and high-level languages in general.
![Click here for going to corresponding publication [J1]](http://www.complang.tuwien.ac.at/markus/researchstatement/img4.png)