 kann also mit der
Formel
kann also mit der
Formel  berechnet werden, wobei b die Basis ist. Z.B. hat die
Binärzahl 101 den Wert
1*22+0*21+1*20=1*4+1*1=5.
berechnet werden, wobei b die Basis ist. Z.B. hat die
Binärzahl 101 den Wert
1*22+0*21+1*20=1*4+1*1=5.
Weiters ist Programmieren eine Fertigkeit, die man sich weniger durch Anhören von Vorlesungen und Lesen von Büchern erwirbt, sondern vor allem, indem man selbst programmiert. Allerdings können Bücher und Vorlesungen helfen, den Horizont zu erweitern, sodass man nicht immer auf den selben Trampelpfaden unterwegs ist.
Zu beachten ist allerdings auch, dass die Informatik nicht nur aus Programmieren besteht.
Es gibt verschiedene Forth-Systeme; für diese LVA verwenden wir Gforth (einige Gforth-spezifische Fähigkeiten werden verwendet). Gforth ist für Linux üblicherweise über die Linux-Distribution verfügbar, und für Windows hier als selbstinstallierendes Executable. Für MacOS X gibt es eine Erfolgsmeldung für das Gforth-Paket auf Homebrew. Fuer Android-Smartphones gibt es Gforth auf Google Play.
Fangen wir damit an, den Computer den Satz einmal schreiben zu lassen:
." I will not do anything bad ever again."Zu beachten ist dabei das Leerzeichen nach
." . Probieren Sie aus, was passiert, wenn
Sie es weglassen. Sie sehen: Computer, insbesondere
Programmiersprachen, sind pedantisch. Dabei
ist ." ein Befehl, oder, in Forth-Terminologie,
ein Wort, der die Eingabe bis zum
nächsten " ausgibt.
Sie können in Gforth mit der Pfeil-Hinauf-Taste die zuletzt eingegebene Zeile (bei wiederholter Anwendung die davor) wieder in die Kommandozeile holen und dann mit der Enter-Taste wieder ausführen, und auf diese Weise die Ausgabe mit wenig Aufwand wiederholen.
Aber auf die Dauer ist es praktischer, wenn wir dieser Aktion einen kurzen Namen geben:
: bart ." I will not do anything bad ever again." ;Jetzt können wir diese Aktion wie folgt ausführen:
bartMit
: bart haben wir die Definition des
Wortes bart angefangen. Danach kam das, was passieren
soll, wenn Sie das Wort ausführen. Die Definition wird
mit ; beendet.
Sie können bart jetzt beliebig oft ausführen:
bart bart bart bart bartDa haben wir auch schon den ersten Fehler: Jede Ausgabe schliesst unmittelbar an die vorige an, anstatt auf einer neuen Zeile zu beginnen. Korrigieren wir das, indem wir
bart anders
definieren:
: bart cr ." I will not do anything bad ever again." ;Das Wort
cr
(für Carriage
Return) bewirkt, dass die Ausgabe am Anfang der nächsten Zeile
fortgesetzt wird.
Jetzt können wir die Ausgabe leicht 20 mal machen lassen:
bart bart bart bart bart bart bart bart bart bart bart bart bart bart bart bart bart bart bart bartDas ist zwar schon eine schöne Ersparnis im Vergleich zur Originalaufgabe, aber noch immer recht repetetiv. Auch das können wir bald besser, aber davor müssen wir uns noch mit Daten befassen. Dann können wir irgendwann auch Programme schreiben, die nicht nur immer das gleiche machen, sondern auch Eingaben verarbeiten und auf sie reagieren.
Umgekehrt kann das selbe Datum auf verschiedene Arten interpretiert werden und hat dann verschiedene Bedeutungen. Zum Beispiel kann die Zahl 65 ein Preis sein, eine Gewichtsangabe, eine Entfernung, usw. Deswegen gibt man in solchen Fällen normalerweise auch die Einheit als Kontext mit an: z.B. EUR65, 65N, 65km.
Interessanterweise hat sich das Arbeiten mit Einheiten in der Programmierung nicht durchgesetzt, obwohl da auch schon einige kostspielige Fehler passiert sind. Jedenfalls werden Zahlen in praktisch allen Programmiersprachen ohne Dimension und ohne Einheit verwendet, und Ihre Bedeutung erhalten Sie durch die Verwendung im Programm.
Auf einer maschinennahen Ebene werden alle Daten irgendwie mit Bits dargestellt. Ein Bit kann zwei Werte annehmen; ein Beispiel wäre, das Geschlecht als Bit darzustellen, die beiden Werte sind dabei "weiblich" und "männlich". Wenn man ein Bit als Zahl interrpetiert, ordnet man diesen beiden Werten üblicherweise die Zahlen 0 und 1 zuordnen. Wie wir sehen werden, kann man es zum Beispiel auch als Vorzeichen interpretieren, und die beiden Zustände sind ">=0" und "<0".
Meist braucht man mehr als zwei verschiedene Werte, um Daten darzustellen, dann verwendet man mehrere Bits. Bei der Darstellung von Zahlen kann man mit n Bits z.B. Zahlen von 0 bis 2n-1 darstellen.
Dabei werden die n Bits als n-stellige Zahl mit der Basis 2
(Binärdarstellung, Binärzahl) interpretiert. Die Zahl mit der
Dartellung
kann also mit der
Formel
berechnet werden, wobei b die Basis ist. Z.B. hat die
Binärzahl 101 den Wert
1*22+0*21+1*20=1*4+1*1=5.
In Forth können wir Zahlen in verschiedenen Basen ein- und ausgeben lassen. Einige Basen können wir direkt eingeben und direkt ausgeben:
%101 dec. #25 dec. $25 dec. %101 hex. #25 hex. $25 hex.Der Präfix
% steht für eine Binärzahl, # für
eine Dezimalzahl, und $ für eine Hexadezimalzahl (Basis
16). Die Ausgabe erfolgt bei dec. dezimal,
bei hex. hexadezimal. Für Binärausgabe gibt es kein
eigenes Wort.
Bei Eingabe von Zahlen ohne Präfix, und bei der Ausgabe
mit u. wird die aktuelle Basis verwendet. Am Anfang ist
die Basis dezimal, aber man kann sie mit n base
! ändern:
#2 base ! %101 u. $95 u. $9559 u. #9559 u. #10 base !Hier sieht man, dass die Binärdarstellung schon bei mittelgroßen Zahlen schnell unübersichtlich wird. Weiters sieht man, dass jede Hex-Ziffer in 4 Binärziffern expandiert wird (denn 24=16): $9=%1001, $5=0101. Im Gegensatz dazu ist die Umrechnung zwischen Dezimal-Darstellung und Binärdarstellung komplizierter. Daher wird in der Informatik gerne die Hexadezimaldarstellung verwendet, wenn man sich mit den Bits beschäftigen will; sie bietet einen guten Kompromiss zwischen Übersichtlichkeit und direkter Beziehung zu den Bits.
%101 dec.Zunächst werden die Zeichen bis zum ersten Leerzeichen, also
%101, als Wort aufgefasst; da es kein Wort mit
diesem Namen im Forth-System gibt, werden die Zeichen dann als Zahl
interpretiert, und diese Zahl dann auf einen Stapel
(englisch: Stack) gelegt (englisch: push, denglisch:
gepusht).
Dann wird das nächste Wort dec. angesehen; dieses wird
im Forth-System gefunden, und ausgeführt. Es nimmt eine Zahl vom
Stack und gibt sie in Dezimaldarstellung aus.
Man kann auch mehrere Werte auf den Stack legen, und dann ausgeben:
#1 #2 dec. dec.Die Werte kommen in der umgekehrten Reihenfolge der Eingabe heraus, weil 2 auf dem Stapel oberhalb von 1 zu liegen kommt, und vom ersten
dec. daher 2 vom Stapel genommen und ausgegeben
wird. Der Stack wird daher auch als last-in first-out (LIFO)
Datenstruktur bezeichnet. Das ist besonders nützlich, wenn man etwas
zwischendrin machen will, z.B.:
#3 base ! 121 #12 base ! u. #10 base !Hier wollen wir eine Zahl mit der Basis 3 eingeben und mit der Basis 12 ausgeben. Da es für Basis 3 keinen Präfix gibt, müssen wir zunächst die Basis mit
#3 base ! auf 3 setzen. Dann
folgt die Zahl 121, die wir eingeben wollen.
Um jetzt in der Basis 12 auszugeben, müssen wir die Basis
mit #12 base ! ändern. Dabei wird auch der Stack
benutzt, aber nach dem ! sind alle Spuren davon
beseitigt, und es liegt nur noch die davor eingegebene Zahl auf dem
Stack, und u. gibt diese Zahl mit der nun aktuellen Basis
12 aus.
Am Schluss schalten wir die Basis wieder auf Dezimal zurück, da es
leicht zu Fehlern führt, wenn man eine andere Basis beläßt (deswegen
empfehle ich allgemein, die Basis möglichst nicht zu ändern, sondern
mit Präfixen und hex. zu arbeiten.
Allgemeiner: es ist meist problematisch, ein Programm so zu gestalten, dass es mit einem globalen Zustand arbeitet (in diesem Fall die Basis). Bei kleinen Programmen kann man so etwas oft noch ohne große Probleme verwenden, aber wenn das Programm wächst, werden solche Techniken schnell unübersichtlich (noch schneller als der Rest).
Wenn Ihr System das Programm xterm installiert hat,
können Sie sich das
Forth-Programm status.fs holen und Gforth mit
gforth status.fsstarten. Dann wird ein Fenster geöffnet, das nach jeder Zeile die aktuelle Basis, den Inhalt des Stacks, und andere Informationen anzeigt. Allerdings müssen Sie das Fenster selbst schliessen, wenn Sie Gforth beenden.
5 4 + u.Das Wort
+ nimmt zwei Werte vom Stack, addiert sie, und
legt das Ergebnis auf den Stack. Daraus ergibt sich bei Berechnungen
eine Postfix-Notation
(der Operator ist hinter den Operanden, auch als UPN bekannt). Das
Wort * multipliziert, - subtrahiert,
und / dividiert (ganzzahlig):
5 4 * u. 5 4 - u. 7 3 / u.Interessanter wird das ganze natürlich bei Rechnungen, die man nicht so ohne weiters im Kopf ausrechnen kann:
12345 67890 * u.Man kann auch komplexere Rechnungen durchführen:
4 2 3 * + u. 4 2 + 3 * u.Wie man sieht, braucht man bei der Postfix-Notation im Gegensatz zur Infix-Notation keine Klammern und auch keine Präzendenzregeln ("Punktrechnung vor Strichrechnung") um die Reihenfolge der Auswertung festzulegen. Programmiersprachen mit Infix-Notation (wie Java) sind aber trotzdem populärer.
Warum sprechen wir davon, dass #33, $21, und %100001 nur verschiedene Darstellungen derselben Zahl sind und nicht verschiedene Zahlen? Weil sich diese Zahl mathematisch gleich verhält, egal wie sie eingegeben wurde. Z.B.:
#33 2 * u. $21 2 * u. %100001 2 * u.Dieses Prinzip, dass wir Daten verschieden darstellen können, dass sie sich aber gleich verhalten, wird uns später bei den abstrakten Datentypen noch einmal begegnen.
In der Hardware werden die Zahlen binär dargestellt, aber davon merken wir bei den bisher verwendeten Rechenoperationen normalerweise nichts. Allerdings haben die Zahlen in Forth (wie auch in den meisten anderen maschinennahen Programmiersprachen) eine begrenzte Größe, und wenn die Grenze erreicht wird, macht sich die binäre Natur schon bemerkbar:
4294967295 u. 4294967295 1 + u. 18446744073709551615 u. 18446744073709551615 1 + u.Wenn Ihr Gforth-System ein 32-bit-System ist, bewirkt schon die erste Addition einen Überlauf, bei einem 64-bit-System erst die zweite. Im Dezimalsystem sieht man den Zahlen das nicht auf den ersten Blick an, aber in der Binärdarstellung und Hexadezimaldarstellung sieht man die Besonderheit:
4294967295 #2 base ! u. #10 base ! 18446744073709551615 #2 base ! u. #10 base ! 4294967295 hex. 18446744073709551615 hex.Die Zahl besteht aus lauter Einsen, wenn man 1 dazuzählt, ergibt sich mathematisch (ohne Überlauf) die Zahl %100000000000000000000000000000000 (alias $100000000) bzw. %10000000000000000000000000000000000000000000000000000000000000000 (alias $10000000000000000), die nicht mehr in 32 Bits bzw. 64 Bits hineinpasst.
Bei arithmetischem Überlauf werden in Forth (und in den meisten maschinennahen Sprachen) die vorderen Stellen einfach abgeschnitten. Das entspricht mathematisch der Operation modulo 232 bzw. 264. Wenn man unbegrenzte Zahlen erwartet, ist dieses Verhalten unerwünscht und führt zu Fehlern, aber es kann auch nutzbringend eingesetzt werden.
0 1 - u.dann erscheint als Ausgabe die uns von vorhin bekannte größte darstellbare Zahl. Auch beim Unterlauf erfolgt die Operation modulo 2n. Wir können dieses Bitmuster aber auch als negative Zahl interpretieren:
0 1 - .Welche Interpretation wir verwenden, drücken wir in Forth dadurch aus, welches Wort wir verwenden: Wenn wir ein Bitmuster als vorzeichenlose ganze Zahl interpretieren und ausgeben wollen, verwenden wir
u., wenn wir es als vorzeichenbehaftete Zahl
interpretieren wollen, verwenden wir ..
In Forth ist es dem Programmierer überlassen, das Programm so zu schreiben, dass die Bitmuster sinnvoll interpretiert werden. Die meisten anderen Programmiersprachen haben ein Typsystem, das auf dieser Ebene eine konsistente Interpretation sicherstellt; allerdings kann das Problem auf höherer Ebene durchaus auch bei Programmiersprachen mit Typsystemen auftreten.
Äquivalenz von -1 zur größten darstellbaren vorzeichenlosen Zahl ergibt sich aus der Äquivalenz bei der Modulo-Arithmetik:
-1 = 2n-1 (mod 2n)
bzw. allgemeiner
-m = 2n-m (mod 2n)
Bei vorzeichenlosen n-Bit-Zahlen ist die kleinste klarerweise 0, und die größte 2n-1. Bei vorzeichenbehafteten Zahlen interpretiert man alle Zahlen, bei denen das höchstwertigste Bit 1 ist, als negativ, und alle, bei denen dieses Bit 0 ist, als >=0; das höchstwertige Bit wird daher auch Vorzeichen-Bit (Sign-Bit) genannt. Die kleinste vorzeichenbehaftete n-Bit-Zahl ist -2n-1, die größte 2n-1-1.
Man kann die Arithmetik modulo 2n auch als Zahlenkreis sehen. Hier ein Beispiel für 4-bit Zahlen:
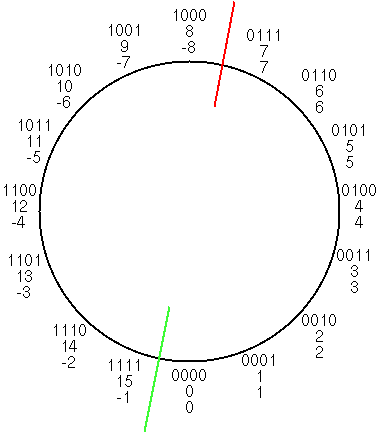
Bei vorzeichenlosen Zahlen findet ein Über- oder Unterlauf statt, wenn die grüne Linie überschritten wird, bei vorzeichenbehafteten Zahlen, wenn die rote Linie überschritten wird.
Diese Darstellung der negativen Zahlen heißt Zweierkomplement-Darstellung, und die hat sich gegenüber anderen Darstellungen durchgesetzt, weil man dafür die gleichen Modulo-Arithmetik-Operationen für Addition, Subtraktion, und Multiplikation verwenden kann wie bei vorzeichenlosen Zahlen. Dementsprechend gibt es in Forth nur ein +, -, * für beide Arten von Zahlen.
Wenn wir diese Idee auf unser Dezimalsystem übertragen, dann würden wir nur Zahlen mit bis zu n Stellen darstellen und innerhalb dieser Zahlen modulo 10n rechnen; nehmen wir als Beispiel n=3, also vorzeichenlose Zahlen von 0 bis 999. Dann legen wir fest, dass wir bei der Verwendung als vorzeichenbehaftete Zahlen die Zahlen 500 bis 999 als negativ betrachten (um den eigentlichen Wert zu bekommen, müssten wir einfach 1000 abziehen, 899 würde also in konventioneller Schreibweise -101 entsprechen). Wir schreiben sie aber weiterhin als 500...999 hin, dann brauchen wir keine Sonderregeln für das Addieren, Subtrahieren, und Multiplizieren dieser Zahlen.
Umgekehrt können wir uns überlegen, unsere übliche Darstellung negativer Zahlen auf den Computer zu übertragen, nämlich die absolute Größe der Zahl (dargestellt wie bei vorzeichenlosen Zahlen) mit einem Vorzeichen zu kombinieren; diese Darstellung heisst sign-magnitude. Da wir auf dieser Darstellung nicht mit Modulo-Arithmetik arbeiten können, stellen wir sie als Linie und nicht als Kreis dar:
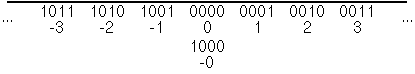
Der Nachteil dieser Darstellung ist, dass man für die Addition, Subtraktion, und Multiplikation eigene Befehle braucht, die sich von denen für vorzeichenlose Zahlen unterscheiden. Wenn Sie zum Beispiel 1001 und 0010 als sign-magnitude-Zahlen addieren, soll 0001 herauskommen, bei der vorzeichenlosen (und 2er-Komplement) Addition dagegen 1011. Auch bei anderen Operationen ergeben sich durch die Zweierkomplement-Darstellung Vorteile.
Allerdings hat die Sign-Magnitude-Darstellung, wie sie (ausserhalb von Computern) üblich ist, auch ihre Vorteile: So ist die übliche Zahlendarstellung nicht auf eine bestimmte Anzahl von Stellen festgelegt (wobei in Computern auch bei der Darstellung beliebig großer ganzer Zahlen die Zweierkomplementdarstellung dominiert).
Welche allgemeine Lehre kann man daraus ziehen: Die naheliegende Lösung ist nicht immer die beste. Andererseits: Man kann beim Abwägen verschiedener Lösungen viel Zeit verschwenden; oft ist es besser, irgendeine Lösung morgen zu haben, als die optimale Lösung in einer Woche. Es hat mehrere Jahrzehnte gedauert, bis sich die Zweierkomplementdarstellung durchgesetzt hat.
: sum-of-3 + + ; 1 2 3 sum-of-3 .Was wir noch nicht können, ist einen übergebenen Wert mehrfach zu verwenden. Wenn wir zum Beispiel eine Zahl quadrieren wollen indem wir sie mit sich selbst multiplizieren, müssen wir sie bis jetzt zwei mal hinschreiben; wenn man einen Wert viele male braucht, ist das nicht praktikabel. Stattdessen merken wir uns den Wert in einer lokalen Variable, die wir dann beliebig oft verwenden können:
: squared { n } n n * ;
5 squared .
Hier wird im Wort squared die lokale Variable n mit Hilfe
von { n } definiert, und später wird sie verwendet. Bei
der Ausführung von squared wird an der Stelle der
Definition ein Wert vom Stack genommen (und in der lokalen Variable
gespeichert). Die Verwendung von n legt diesen Wert dann auf den
Stack. Am Ende von squared verschwindet die lokale
Variable.
Betrachten wir einen kompliziereren Fall:
: squared { n } n n * ;
: foo { n } n squared squared n * ;
3 foo .
Was berechnet foo? Welchen Wert hat n an welcher Stelle? Insbesondere:
Welchen Wert hat das letzte Vorkommen von n in foo?
Squared und foo haben jeweils ihr eigenes n; tatsächlich hat sogar jeder Aufruf von squared und foo eigene Exemplare (in Informatiksprech: Instanzen) von n. Das heißt, n hat in foo den Wert 3, bei jeder Verwendung. Beim ersten Aufruf von squared hat n ebenfalls den Wert 3; dieser Aufruf legt 9 auf den Stack, und dieser Wert wird dann im zweiten Aufruf von squared in n gespeichert; n hat also im zweiten Aufruf von squared den Wert 9. Der zweite Aufruf legt 81 auf den Stack; danach wird wieder das n von foo, also 3, auf den Stack gelegt, und mit 81 multipliziert; Ergebnis: 243. Man kann sich allgemein überlegen, dass foo den Wert (n2)2*n=n5 berechnet.
Praktisch alle Programmiersprachen haben lokale Variablen, die sich so verhalten.
: bart cr ." I will not do anything bad ever again." ; : tafel 20 0 ?do bart loop ;
?do Schleifenrumpf loop nimmt zwei Werte (das
Limit, hier 20, und der Startwert, hier 0) vom Stack und
führt Schleifenrumpf d mal aus, wobei d die
Differenz der beiden Werte ist.
Dabei kann man mit i den Schleifenzähler abfragen:
: test ?do i . loop ; 10 0 test 5 3 testBeim ersten Durchlauf (Iteration) ist der Schleifenzähler gleich dem Startwert, wenn das Limit erreicht ist, wird die Schleife nicht mehr durchlaufen.
I verhält sich dabei ähnlich wie eine
lokale Variable (auch wenn es einige Unterschiede gibt). Hier eine
Anwendung:
: fac { n } n n 1 ?do i * loop ;
5 fac .
Wobei dieses Programm verständlicher wird, wenn man es etwas
umformattiert und etwas dokumentiert:
: fac { n -- n! }
n
n 1 ?do ( n1 )
i *
loop ;
5 fac .
In diesem Programm ist im Gegensatz zu den bisherigen der Stack nicht
leer, wenn ein Schleifendurchlauf beginnt und endet, was das
Verständnis etwas erschwert. Daher dokumentieren wir den Inhalt des
Stack am Anfang eines Durchlaufs mit dem Kommentar ( n1
).
Und wenn wir schon dabei sind, dokumentieren wir auch noch den
Stack-Effekt der gesamten Definition. Traditionell macht man
das in Forth mit Kommentaren wie ( n -- n! ) (mit runden
Klammern); vor -- schreibt man die Stack-Elemente, die
das Wort vom Stack nimmt, hinter -- die Stack-Elemente,
die das Wort auf den Stack legt.
Da die Definition von lokalen Variablen oft am Anfang der
Wort-Definition erfolgt, kann man diese Definition auch als
Stack-Effekt hinschreiben: { n -- n! } (mit
geschwungenen Klammern im Gegensatz zu runden), wobei --
n! ignoriert wird.
Die Zeilenumbrüche und Einrückungen sollen die Kontrollstruktur deutlich machen. Dabei hat man in der Formattierung in Forth wie in den meisten Sprachen große Freiheiten, die praktisch immer so genutzt werden, und das ist auch sehr empfehlenswert. Einige Programmiersprachen (z.B. Python) verlangen sogar so eine Einrückung, um den Geltungsbereich der Kontrollstruktur festzulegen.
5 3 < . -5 -3 < . 5 3 u< . -5 3 u< . 3 3 = .Vergleiche liefern in Forth 0 für "falsch" und -1 für "wahr". Man kann auf der Grundlage von Vergleichen unterschiedliche Wörter ausführen:
: max { a b -- c }
a b < if
b
else
a
endif ;
3 5 max .
-3 -5 max .
: abs { n -- n1 }
n
n 0 < if ( n )
negate
endif ;
3 abs .
-3 abs .
if then-Zweig else else-Zweig endif nimmt einen
Wert vom Stack. Ist er 0, wird else-Zweig
bzw. bei Nichtvorhandensein einer else-Klausel gar nichts
ausgeführt, ansonsten then-Zweig (so genannt, weil bei
manchen Sprachen dort ein then steht, wo in Forth
das if steht). Anschliessend fährt die Ausführung hinter
dem endif fort.
negate hat den Stack-Effekt ( n -- -n ).
Wenn, wie hier, mehrere lokale Variablen in einer Definition definiert werden, erhaelt die rechteste definierte lokale Variable den obersten Wert auf dem Stack, die nächste von rechts den nächsten Wert auf dem Stack, usw.
: digits ( n -- )
begin { n }
n while
n 10 mod .
n 10 /
repeat ;
1234 digits
[Hier werden die Ziffern in der umgekehrten Reihenfolge ausgegeben wie
gewöhnlich, und wir verwenden ein Wort zur Ausgabe der Ziffern, das
selbst die komplette Umwandlung machen kann; wir werden diese Makel
später beheben.]
Eine begin Rumpf1 while Rumpf2
repeat Schleife führt zunächst Rumpf1 aus.
Das while nimmt einen Wert vom Stack; ist er 0
(Abbruchbedingung), wird die Ausführung der Schleife
hinter repeat fortgesetzt; ansonsten
wird Rumpf2 ausgeführt, und dann beginnt die Ausführung der
Schleife von vorne.
mod ( n1 n2 -- n3 ) berechnet den Rest der Division
von n1 durch n2 (Modul).
digits übergibt.
Bei einem negativem Parameter ist das allerdings nicht der Fall:
Gforth rundet bei der ganzzahligen Division in Richtung
-∞. -1 10 / ergibt -1, und alle negativen Zahlen
erreichen bei wiederholter Division durch 10 irgendwann -1, und
daraufhin wiederholt sich die Schleife endlos (Abbruch in Gforth mit
Ctrl-C).
Um digits also so aufzurufen, dass es terminiert, muss
der Wert auf dem Stack also ≥0 sein. Das ist
die Vorbedingung für die Schleife und
für digits. Wir werden uns später noch eingehender mit
Vorbedingungen beschäftigen.
Termination ist in der theoretischen Informatik ein wichtiges Thema: Man kann kein Programm schreiben, das von einem beliebigen Programm feststellt, ob es terminiert oder nicht (Entscheidbarkeit).
In der Praxis ist Termination aber normalerweise kein großes Problem; die Fälle, die in der Theorie Schwierigkeiten machen, vermeidet man im Normalfall, und in den meisten Fällen ist es recht einfach, festzustellen, dass man sich der Abbruchbedingung nähert (der Fall oben ist schon relativ kompliziert). Dass der Rest der Schleife das tut, was man gerne hätte, ist in den meisten Fällen schwieriger hinzubekommen.
Aber auch wenn es nicht sehr schwer ist, muss man es trotzdem machen, zum Beispiel beim Test; auch wenn Sie die Aufgabe nicht komplett hinbekommen, werden Sie für eine Schleife, die endet, mehr Punkte bekommen als für eine Endlosschleife, zumindest wenn die Schleife mit der Problemstellung zu tun hat.
Es ist nicht offensichtlich, wohin sich die Folge entwickelt. Wir könnten das jetzt per Hand für ein paar Werte von x0 ausrechnen, aber das ist auf die Dauer etwas langwierig, also schreiben wir ein Programm dafür. Zunächst die Berechnung des nächsten Elements der Folge:
: step { xn -- xn1 }
xn 2 mod 0 = if
xn 2 /
else
xn 3 * 1 +
endif ;
13 step .
Jetzt können wir uns mit einer Zählschleife eine feste Anzahl von
Werten der Folge anzeigen lassen:
: steps ( x0 k -- )
0 ?do { xn }
xn .
xn step
loop drop ;
13 20 steps
9 20 steps
7 20 steps
Es schaut so aus, als ob die Folge bei x0≥1 irgendwann
den Zyklus 4 2 1 erreicht. Ist dieser Zyklus erreicht, so bleibt die
Folge in dem Zyklus. Wir können jetzt eine allgemeine Schleife
schreiben, die sich so lange wiederholt, bis 1 erreicht ist:
: steps-to-1 ( x0 -- )
begin { xn }
xn 1 <> while
xn .
xn step
repeat ;
7 steps-to-1
Das ist möglicherweise eine Endlosschleife; wir wissen ja nicht, ob
jede Folge irgendwann 1 erreicht. Aber da der Zweck dieses Programms
die Erkundung ist und nicht das Lösen eines gegebenen Problems, ist
das hier akzeptabel.
Üblicherweise betrachtet man das Verhalten zur Laufzeit, indem man einfach die Schritte des Programms durchgeht; "Debugger" verfügen üblicherweise über eine Step-Funktion, die einem dabei unterstützt (von deren Verwendung ich aber in den meisten Fällen abrate, weil es wesentlich effektivere Methoden gibt, um Fehler zu lokalisieren).
Aber man kann die ausgeführten Schritte auch hinschreiben, und erhält so einen Trace.
Als einfaches Beispiel betrachten wir einen Trace zu einem einfachen Programm:
: bla 1 - 3 * ; : blub 2 * bla 3 bla + ;Der Trace für
5 blub . ist:
5 2 * 1 - 3 * 3 1 - 3 * + .In diesem Trace und in den folgenden ist der Kontrollfluss (z.B. Aufrufe und die Rückkehr von Aufrufen) weggelassen, da der ja schon in den im Trace vorkommenden Worten widergespiegelt ist.
Betrachten wir als nächstes Beispiel:
: squared { n } n n * ;
: foo { n } n squared squared n * ;
3 foo .
Hier stellen wir den Anfang und das Ende des Sichtbarkeitsbereichs von
lokalen Variablen (der hier mit den Aufrufem und der Rückkehr von den
Aufrufen übereinstimmt) mit ( ) dar, weil das nötig ist,
um zu erkennen, welche Verwendung von n zu welcher Definition gehört.
3 ( { n } n ( { n } n n * ) ( { n } n n * ) n * ) .
Leider kann man diese Sequenz nicht direkt in Forth verarbeiten, weil
lokale Variablen nur in Definitionen funktionieren (und die Klammern
in Forth eine andere Bedeutung haben). Wir können die lokalen
Variablen auch auflösen, dann erhalten wir eine ausführbare Sequenz:
3 ( { n } n ( { n } n n * ) ( { n } n n * ) n * ) .
3 drop 3 drop 3 3 * drop 9 9 * 3 * .
Drop entfernt das oberste Element des Stacks.
Etwas interessanter wird das Ganze, wenn Kontrollstrukturen in's Spiel kommen:
13 steps-to-1 4 steps-to-1Wir zeigen im folgenden die Kontrollflusswörtern
if
while, weil sie neben ihrer Kontrollflussfunktion einen Wert
vom Stack nehmen (was im Trace äquivalent zu drop ist).
13
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 3 * 1 + ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 3 * 1 + ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while )
.
4
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while n . n ( { n } n 2 mod 0 = if n 2 / ) )
( { n } n 1 <> while )
.
Hier sehen, wir, dass ein Programm zur Laufzeit meist verschiedene
Abläufe abhängig von der Eingabe hat, und dass schon kurze Läufe viele
Schritte ausführen können. Ein Fehler kann in einem Lauf (mit einer
Eingabe) auftreten und in einem anderen (mit anderer Eingabe) nicht.
Es ist daher oft nicht zielführend, über ein Programm nur anhand eines konkreten Laufs bzw. Traces nachzudenken.
Daher sollte man zusätzlich von diesen verschiedenen Abläufen abstrahieren und gemeinsame Eigenschaften über alle Läufe erkennen. Bzw. umgekehrt das Programm so schreiben, dass man mit einer Beschreibung wichtige Eigenschaften aller Läufe erfasst.
Die Repräsentation des Programms über alle Abläufe ist der Text des Programms (auch Quelltext, Quellcode oder Source code genannt), daher geht man bei solchen Beschreibungen mit dem Programmtext. Da der Programmtext feststeht, nennt man so eine Beschreibung statisch, während eine Betrachtung, die sich auf einen konkreten Lauf bzw. Eigenschaften zur Laufzeit bezieht, dynamisch genannt wird. Im folgenden sehen wir einige Beispiele, und das Thema wird uns auch im Rest des Semesters begleiten.
In Forth ist es zum Beispiel im Prinzip möglich, dass ein Wort zur Laufzeit einen beliebigen, stark von den Eingabedaten abhängigen Stack-Effekt hat (also einen dynamischen Stack-Effekt). Allerdings kann man solche Wörter nicht vernünftig einsetzen und Programme mit solchen Wörtern nur schwer, wenn überhaupt, verstehen. Daher sind solche Wörter und Programme in Forth unüblich. Die Stack-Tiefe ist normalerweise an einer bestimmten Stelle immer gleich, egal auf welchem Weg diese Stelle erreicht wurde; und selbst bei den wenigen Ausnahmen davon kommen nur Dinge vor, die man auf einer höheren Ebene wieder statisch verstehen kann.
Das spiegelt sich auch in der Dokumentation wieder:
: fac { n -- n! }
n
n 1 ?do ( n1 )
i *
loop ;
5 fac .
Hier sagt der Kommentar ( n1 ), dass an dieser Stelle
genau ein Element über dem Grundniveau auf dem Stack liegt, egal mit
welchem Parameter fac aufgerufen wird und wie oft die
Schleife durchlaufen wird (das Grundniveau sind die Elemente auf dem
Stack, die von fac nicht berührt werden sollen, die also unter dem
Parameter n auf dem Stack liegen).
Man kann das auch an den anderen Beispielen sehen, die wir bisher gesehen haben:
Bei Schleifen ist der Rumpf so gestaltet, dass die
Stacktiefe am Anfang und am Ende des Rumpfs gleich sind. Wenn man
einen Wert auf dem Stack bearbeiten will, muss man ihn schon vor der
Schleife drauflegen, wie bei fac geschehen, und
ggf. nachher wieder entfernen.
Bei bedingter Ausführung muss der then-Zweig den selben Effekt auf die Stack-Tiefe haben wie der else-Zweig. Wenn es keinen else-Zweig gibt, darf der then-Zweig die Tiefe nicht ändern.
Betrachten wir als Beispiel
: abs { n -- n1 }
n
n 0 < if ( n )
negate
endif ;
Hier haben wir einen then-Zweig, der die Stack-Tiefe nicht ändert,
dafür mussten wir das eventuell negierte n schon deutlich früher auf
den Stack legen. Eine andere Lösung wäre:
: abs { n -- n1 }
n 0 < if ( n )
n negate
else
n
endif ;
Da hier im then-Zweig etwas auf den Stack gelegt wird, brauchen wir
auch einen else-Zweig, der etwas auf den Stack legt. Falsch wäre:
: abs { n -- n1 } \ falsch!
n 0 < if
n negate
endif ;
Allerdings merken Sie diesen Fehler in Forth erst beim Testen:
-5 abs . 5 abs .
Die Stack-Tiefe ist nur ein Beispiel. Auch wenn die meisten anderen Programmiersprachen keinen expliziten Stack haben und diese spezielle Eigenschaft dort keine Rolle spielt, es gibt immer eine Menge Eigenschaften, die man statisch verstehen möchte, und wir werden noch weitere Beispiele sehen.
Schauen wir uns noch einmal unser fac-Beispiel an:
: fac { n -- n! }
n
n 1 ?do ( n1 ) \ n1 = (i-1)!*n
i * ( n2 ) \ n2 = i!*n
loop ( n3 ) \ n3 = (n-1)!*n = n!
;
Hier haben wir Kommentare wie ( n2 ) \ n2 = i!*n
geschrieben.
Den ersten Teil ( n2 ) haben wir schon besprochen.
Dieses sogenannte Stack-Bild kann man auch als Invariante über die
Stack-Elemente sehen.
Der Kommentar dahinter, der mit
\ eingeleitet wird, ist eine Invariante bezüglich des
Wertes von n2.
Betrachten wir noch einmal das Wort fac. Wie bin ich
dazu gekommen, und gibt es noch andere Möglichkeiten?
Fangen wir mit der mathematischen Formel an:
n!=1*2*3*...*n
In Postfix-Syntax ist das:
1 2 * 3 * ... n *
Das kann man jetzt als gewünschten Trace auffassen. Die
aufsteigende Folge von Zahlen legt die Verwendung einer Zählschleife
nahe, wobei die Zahlen direkt über den Zähler i generiert werden
können. Dann hätten wir also den Schleifenrumpf i *
bzw. die Schleife (ohne Parameter):
?do i * loopIm Schleifenrumpf legt
i ein Element auf den
Stack, * nimmt 2 Elemente vom Stack und legt wieder eines
drauf. Die Stacktiefe ändert sich also im Schleifenrumpf nicht, in
dieser Hinsicht ist die Schleife schon einmal in Ordnung. Allerdings
muss schon vor dem Schleifenrumpf ein Element auf dem Stack liegen,
was wir mit einem Stack-Bild ausdrücken:
?do ( n1 ) i * loopWenn wir
i von 2 bis n gehen lassen wollen, dann müssen
wir die Schleifenparameter so hinschreiben:
: fac { n -- n! }
...
n 1 + 2 ?do ( n1 )
i *
loop
... ;
Aus der obigen Postfix-Formel haben wir "1" noch nicht in dem Programm
untergebracht, das ist ein naheliegender erster Wert für n1:
: fac { n -- n! }
1
n 1 + 2 ?do ( n1 )
i *
loop
... ;
Müssen wir noch etwas machen? Überlegen wir uns
Schleifeninvarianten:
: fac { n -- n! }
1
n 1 + 2 ?do ( n1 ) \ n1 = 1*2*..*(i-1)=(i-1)!
i * ( n2 ) \ n2 = 1*2*..*i = i!
loop ;
Da der letzte Wert von i=n ist, haben wir am Ende n! auf dem Stack,
wir brauchen also nichts weiter machen.
Allerdings ist die Vorbedingung dieser Schleife n≥1, da sonst
die Grenze der Zählschleife kleiner ist als der Startwert. Wir können
den Startwert allerdings auch auf 1 setzen. Das bewirkt in den
meisten Fällen einen zusätzlichen Schleifendurchlauf, der 1
* bewirkt, was auf das Ergebnis keinen Einfluss hat. Im Fall
n=0 sorgt er dafür, dass die Schleife nicht ausgeführt wird und das
Ergebnis gleich 1 ist (entsprechend 0!=1, wie in der Methematik
definiert):
: fac { n -- n! }
1
n 1 + 1 ?do ( n1 ) \ n1 = 1*1*2*..*(i-1)=(i-1)!
i * ( n2 ) \ n2 = 1*1*2*..*i = i!
loop ;
Früher haben wir die folgende Variante gesehen:
: fac { n -- n! }
n
n 1 ?do ( n1 ) \ n1 = (i-1)!*n
i * ( n2 ) \ n2 = i!*n
loop ( n3 ) \ n3 = (n-1)!*n = n!
;
Hier wird die Multiplikation mit n in der Schleife eliminiert, indem
wir am Anfang n statt 1 auf den Stack legen. Man erspart sich dadurch
das 1 + beim Berechnen der Schleifenparameter.
Allerdings hat diese Variante auch n≥1 als Vorbedingung.
Auf diese Schleife bin ich gekommen, indem ich mir wie oben den Schleifenrumpf überlegt habe. Bei den Schleifenparametern bin ich zunächst von n 0 ausgegangen, denn das ist für Zählschleifen der Normalfall in Forth; allerdings würde das f0*0*1*..*(n-1) ergeben (f0 ist Anfangswert), wobei 0 schon einmal unerwünscht ist. Das habe ich korrigiert, indem ich n 1 als Schleifenparameter gewählt habe, macht f0*1*..*(n-1)=f0*(n-1)!. Dann kam die Idee, dass ich mit f0=n zu meinem gewünschten Resultat käme. Den Fall n=0 habe ich mir dabei offensichtlich nicht überlegt; Fehler an den Grenzen des Eingabebereichs sind übrigens häufig.
Das geht für Programme mit mathematischer Aufgabenstellung wie unser fac-Beispiel recht gut; im Allgemeinen ist es aber sehr aufwendig, ein größeres Programm formal zu spezifizieren, und dann die Übereinstimmung des Programms mit der Spezifikation zu beweisen.
Und dabei ist die Frage: Beschreibt die formale Spezifikation das, was wir von dem Programm erwarten? Auch in der Spezifikation können Fehler vorkommen.
Es gibt durchaus einige Bereiche, in denen formale Methoden erfolgreich verwendet werden, aber meistens überprüft man damit nur einen Teil der Eigenschaften, die wir vom Programm erwarten, und zwar die, die mit formalen Methoden gut und verständlich spezifiziert und überprüft werden können, und die mit anderen Methoden schlecht zu überprüfen sind. Ein berühmtes Beispiel ist die Überprüfung von Windows-Treibern auf Fehler durch gleichzeitige Ausführung (z.B. auf mehreren Kernen eines Multi-Core-Prozessors); Microsoft stellt ein Werkzeug zur Verfügung, um die Abwesenheit solcher Fehler formal zu beweisen. Das beweist noch nicht, dass der Treiber funktioniert wie erwartet, aber immerhin, dass er eine bestimmte Art von Fehler nicht hat.
Wir können weitere Eingaben verwenden und die Ausgaben für diese Eingaben prüfen (weitere Testfälle), und können so das Vertrauen in die Korrektheit des Programmes steigern.
Ein großer Vorteil solcher Testfälle ist, dass sie (im Vergleich zu einer formalen spezifikation) relativ leicht verständlich sind, und es daher seltener vorkommt, dass der Testfall von dem abweicht, was man vom Programm erwartet.
Damit das möglichst effektiv geschieht, sollte man aber nicht einfach irgendwelche Testfälle verwenden, sondern mit System vorgehen.
Ein Grundsatz dabei ist, die Testfälle alle Teile des Codes einmal ausführen sollten (Coverage). Ein Testfall kann einen Fehler in einem Stück Code ja nur dann finden, wenn er es ausführt.
Unser fehlerhaftes abs-Beispiel zeigt, dass das nicht reicht:
: abs { n -- n1 } \ falsch!
n 0 < if
n negate
endif ;
-5 abs . .s
Hier führt der Testfall jedes Wort in abs aus (statement
coverage), trotzdem wird der Fehler nicht gefunden. Man muss
also auch Testfälle haben, die Zweige ausführen, die keinen Code
enthalten (branch coverage), in diesem Fall mit "5 abs
.". Es gibt auch noch
weitere Coverage-Kriterien,
auf die wir hier aber nicht weiter eingehen.
Bei komplexeren Programmen ist es übrigens oft schwierig, 100% Coverage zu erreichen, da ein Teil des Codes für die Behandlung von Fehlern da ist, die normalerweise nicht auftreten (z.B. ein Fehler durch eine kaputte Festplatte), oder nach der aktuellen Programmlogik gar nicht auftreten können (aber möglicherweise nach Änderungen im Programm schon).
Eine häufige Fehlerquelle ist, bei Abfragen für Schleifenenden oder
bedingungte Ausführung auf z.B. n statt auf n+1 oder n-1 abzufragen,
oder > statt >= zu schreiben oder
umgekehrt. Auf diese sogenannten off-by-one-Fehler können
Sie testen, indem Sie die Testfälle so gestalten, dass sie in dem
Bereich, in dem die Verzweigung in die andere Richtung ausfallen
würde, eben genau die beiden Grenzwerte abtestet. Bei
unserem abs-Beispiel wären das die Testfälle:
0 abs . .s -1 abs . .sDa der 0-Fall in diesem Fall nicht besonders aussagekräftig ist, würde ich auch noch
1 abs . .shinzufügen.
Wenn wir das fac-Beispiel betrachten, und ein Wort
haben wollen, das auch 0! korrekt berechnet, dann ist ein guter Testfall
0 fac . .sDer würde unsere beiden Implementierungen mit der Vorbedingung n≥1 sofort als "nicht der Anforderung entsprechend" entlarven. Weitere Testfälle für
fac wären:
1 fac . .s \ weiterer off-by-one Test 3 fac . .s \ passt die Multiplikation?
Man kann die Testfälle auch unabhängig von dem Code schreiben, den man testen will (black box testing); solche Tests sollten dann für alle möglichen Programme verwendbar sein, die die Anforderungen erfüllen. Teilweise werden sogar die Tests als (partielle) Spezifikation der Anforderungen entwickelt und vor dem Programm geschrieben (Test-Driven Development).
Da man Black-Box-Tests nicht auf die konkrete Programmstruktur
abstellen kann, hat man weniger Orientierung, was man Testen soll.
Aber man kann sich an Grenzwerten in der Spezifikation bzw. in den
Anforderungen orientieren; diese werden wohl auch zu Verzweigungen im
Code führen, und dort kann man dann Testfälle um diese Grenzwerte
herumgruppieren. Bei abs kommen wir dabei auf die
gleichen Testfälle.
Bisher haben wir bei den Tests nur die Eingabe spezifiziert, und die Ausgabe dann mit unseren Augen überprüft. Das ist unpraktisch, wenn man die Tests mehrfach durchführen will oder unabhängig von den Programmen den kompletten Testfall hinschreiben will (was besonders beim Black-box-Testen vorkommt). Daher gibt es auch Möglichkeiten, die Ausgabe eines Tests zu spezifizieren. Wenn Sie Gforth mit
gforth test/ttester.fsstarten, dann steht ihnen so ein Werkzeug zur Verfügung, wobei Ausgaben auf dem Stack überprüft werden:
t{ -1 abs -> 1 }t
t{ 0 abs -> 1 }t
t{ 1 abs -> 1 }t
Da auch Testen die Korrektheit nicht beweist, kombiniert man es am besten mit anderen Methoden, um Fehler zu finden. Eine gute Ergänzung zum Testen ist Code Review, wo man den Programmcode mit jemandem zusammen durchgeht, der ihn nicht geschrieben hat.
In der Lehrveranstaltung Übersetzerbau bewerte ich die abgegebenen Programme in erster Linie mit (Black-Box-)Tests. Zusätzlich kommt es zu einem Gespräch, indem die Studentinnen und Studenten die von ihnen abgegebenen Programme erklären müssen. Oft entdecke ich dabei noch Fehler, die durch die Testfälle nicht aufgedeckt wurden.
Jedes Byte kann einzeln angesprochen werden, es hat eine Adresse, die natürlich auch wieder ein Bitmuster ist, das man üblicherweise als vorzeichenlose Zahl interpretiert und oft in Hexadezimaldarstellung hinschreibt.
Ein Programm, das auf einem Betriebssystem mit Speicherschutz (wie
Linux, Windows, oder MacOS X) läuft, kann nicht auf jede beliebige
Adresse zugreifen, sondern nur auf Speicherbereiche, die das
Betriebssystem dem Programm zur Verfügung stellt. In Forth können Sie
mit dem Wort c@ ( addr -- c ) (ausgesprochen "C-Fetch")
das Byte c von der Adresse addr lesen. Probieren wir das einmal an
irgendeiner Stelle:
1234 c@ .Wenn Ihr Betriebssystem dem Forth-System nicht zufällig den Speicher an der Adresse 1234 zur Verfügung stellt, sehen Sie eine Fehlermeldung wie
:1: Invalid memory address 1234 >>>c@<<< . Backtrace:Dann hat der Speicherschutz zugeschlagen; in diesem Fall wurde der Fehler vom Forth-System abgefangen; wenn ein Programm so einen Fehler nicht abfängt, produziert das Betriebssystem eine Fehlermeldung wie "Segmentation fault" (Unix) oder "General protection fault" bzw. "Allgemeine Schutzverletzung" (Windows).
Auf welchen Speicher können wir jetzt zugreifen? In Forth gibt es einen großen Speicherbereich namens "Dictionary":

Die konkreten Zahlenwerte für die Adressen variieren von System zu System und sind hier nur beispielhaft angegeben. Wir können uns jetzt die Bytes in diesem Speicherbereich anschauen, z.B.:
forthstart c@ . forthstart 1 + c@ .
Das wird auf die Dauer etwas mühsam, aber wir können ja ein Wort
schreiben, das uns das ganze etwas erleichtert. Da so ein Wort öfters
benötigt wird, gibt es schon so eines in Forth: dump ( addr u --
) zeigt das Byte an Adresse addr und die folgenden, insgesamt u
Bytes (also bis inklusive addr+u-1). Beispiel (mit Ausgabe):
forthstart 80 dump 7FF262A56030: 30 60 A5 62 F2 7F 00 00 - 65 87 CB BD 52 37 C8 2B 0`.b....e...R7.+ 7FF262A56040: B0 72 05 00 00 00 00 00 - 00 00 80 00 00 00 00 00 .r.............. 7FF262A56050: 00 40 00 00 00 00 00 00 - 00 40 00 00 00 00 00 00 .@.......@...... 7FF262A56060: 00 3C 00 00 00 00 00 00 - 00 3A 00 00 00 00 00 00 .<.......:...... 7FF262A56070: 80 06 A6 62 F2 7F 00 00 - D0 E7 A6 62 F2 7F 00 00 ...b.......b....
Dump zeigt in jeder Zeile die Adresse des ersten Bytes
der Zeile an (als Hex-Zahl), und danach 16 Bytes auf zwei Arten an:
als Hex-Zahl, und, wenn es ein anzeigbares ASCII-Zeichen ist, als
Zeichen (sonst als .). Wir sehen also im dump, dass an Adresse
$7FF262A56030 das Byte $30 steht, was der ASCII-Code für das Zeichen
"0" ist; an der nächsten Adresse $7FF262A56031 steht das Byte $60, als
Zeichen "`"; usw.
Der Speicherbereich heißt deswegen Dictionary, weil dort die
Forth-Wörter gespeichert sind. Wenn wir ein Wort dazufügen, wird es
am Anfang des bisher freien Speichers gespeichert,
und here verschiebt sich:
here here : bart cr ." I will not do anything bad ever again." ; here cr .s - negate dump <3> 140141316031200 140141316031200 140141316031368 7F75315C42E0: D8 27 5C 31 75 7F 00 00 - 04 00 00 00 00 00 00 80 .'\1u........... 7F75315C42F0: 62 61 72 74 20 20 20 20 - AA 43 40 00 00 00 00 00 bart .C@..... 7F75315C4300: 00 00 00 00 00 00 00 00 - F8 44 40 00 00 00 00 00 .........D@..... 7F75315C4310: D8 22 57 31 75 7F 00 00 - 1B 46 40 00 00 00 00 00 ."W1u....F@..... 7F75315C4320: 50 43 5C 31 75 7F 00 00 - 49 20 77 69 6C 6C 20 6E PC\1u...I will n 7F75315C4330: 6F 74 20 64 6F 20 61 6E - 79 74 68 69 6E 67 20 62 ot do anything b 7F75315C4340: 61 64 20 65 76 65 72 20 - 61 67 61 69 6E 2E 20 20 ad ever again. 7F75315C4350: 68 4D 40 00 00 00 00 00 - 28 43 5C 31 75 7F 00 00 hM@.....(C\1u... 7F75315C4360: 68 4D 40 00 00 00 00 00 - 26 00 00 00 00 00 00 00 hM@.....&....... 7F75315C4370: A0 45 40 00 00 00 00 00 - 88 1F 57 31 75 7F 00 00 .E@.......W1u... 7F75315C4380: 5B 45 40 00 00 00 00 00 - [E@.....Hier sehen wir den Speicher, der vom Wort
bart belegt
wird. Zu erkennen ist dabei der Name des Wortes, und der Text, den
das Wort ausgibt, der Rest besteht aus Verwaltungsinformation für das
Forth-System und aus einer anderen Repräsentation des Programmcodes.
Hier sehen wir schon, dass der Quellcode normalerweise nicht direkt
ausgeführt wird, sondern entweder in Maschinensprache übersetzt
(compiliert) wird, oder zumindest (wie hier) in eine Form,
die relativ schnell ausgeführt werden kann.
Als nächstes wollen wir unseren eigenen Speicherbereich reservieren, in dem wir tun und lassen können, was wir wollen:
here 10 allot constant aHier reservieren wir uns 10 Bytes mit mit
allot ( u -- ),
und speichern die Anfangsadresse dieses Speicherbereichs in einer
Konstante a. Dabei darf die Definition von a erst nach
dem allot erfolgen, da constant ja selbst
Speicher im Dictionary reserviert und here weiterbewegt:
a here a - dumpWir können jetzt Bytes in diesen Bereich schreiben:
$25 a c! $35 a 1 + c! $45 a 2 + c!... und von dort wieder auslesen:
a 1 + c@ hex.bzw. den Speicherbereich anschauen:
a 10 dump
c! (ausgesprochen "C-Store") hat den Stack-Effekt (
c addr -- ) und schreibt das Byte c an die Adresse addr.
c@)
addressieren zu können, ist man bei PCs seit 2003 und bei Smartphones
seit 2013 auf 64-bit-Maschinen umgestiegen, mit denen Adressräume bis
zu 16 EB (oder 4 Milliarden mal groesser als bei 32-bit-Maschinen)
möglich ist.
Die Größe der Adressen bestimmt auch die Größe der effizient verarbeitbaren ganzen Zahlen, da mit den Adressen auch gerechnet wird, wie wir sehen werden. Diese Größe nennt man in der Computerarchitektur auch die Wortgröße. Allerdings hat "Wort" in Forth eine andere Bedeutung, daher verwenden wir in Forth stattdessen der Begriff Zelle (cell).
[Leider wird "Wort" bzw. "word" auch in den Assemblerhandbüchern diverser Prozessorhersteller anders verwendet: Es bezeichnet die Adressgröße des Urahns einer Familie von Prozessoren; so verwendet Intel (dominant bei PCs) auch auf 64-bit-Prozessoren "Word" für 16 bits, weil der Urahn 8008 Adressen in 16 bits speicherte, während ARM (dominant bei Smartphones) "Word" für 32 bits verwendet.]
Auf Gforth ist die Zellengröße 64 bits oder 32 bits (wobei der Windows-Port derzeit ein 32-bit-Programm ist; das läuft auch auf 64-bit-Versionen von Windows, hat aber 32-bit-Zellen und daher nur 4GB Adressraum). Sie können sich die Zellengrösse in Bytes mit
1 cells .anzeigen lassen.
cells ( n1 -- n2 ) multipliziert den
Wert auf dem Stack mit der Anzahl der Bytes pro Zelle. Wenn wir also
z.B. Speicher für 10 Zellen reservieren wollen, können wir das so
machen:
here 10 cells allot constant bJetzt können wir eine Zelle am Anfang dieses Bereichs speichern:
$1234567890abcdef b ! b 1 cells dump
! ( x addr -- ) ("Store") speichert x an die Stelle addr.
Der Dump auf meinem Computer::
7F702E2D72E0: EF CD AB 90 78 56 34 12 - ....xV4.Wenig überraschend benötigt die Speicherung mehrere Bytes, und zwar auf diesem 64-bit-System 8 Bytes. Das niederwertigste Byte wird an der niedrigsten Adresse gespeichert, und das höchstwertige an der höchsten. Diese Speicherung heißt little-endian. Wenn wir einen andere Wert in unserem Speicherbereich speichern wollen, ohne den ersten zu zerstören, müessen wir frühestens 8 Bytes, also eine Zelle, später beginnen:
$fedcba0987654321 b 1 cells + ! b 2 cells dump b @ hex.
@ ( addr -- x ) ("Fetch") liest die Zelle an der Adresse
addr und legt den Inhalt auf den Stack. Wenn wir dagegen versuchen
würden, den zweiten Wert an der Adresse b 1 + zu
speichern, würde der erste Wert teilweise Überschrieben:
$1111111111111111 b 1 + ! b 2 cells dump b @ hex.[Manche Prozessoren können nur auf durch die Zellengröße teilbare Adressen zellenweise zugreifen (Ausrichtung oder Alignment) und liefern in diesem Fall einen Fehler.]
Wenn wir ein Array A von Zellen haben und auf einen Index k zugreifen möchten, geht das einfach mit
A k cells + @ ( x ) \ Lesen
( x ) A k cells + ! \ Schreiben
Bei einem Array B von Bytes geht es noch etwas einfacher:
B k + c@ ( c ) \ Lesen
( c ) B k + c! \ Schreiben
Wobei der Index dabei jeweils bei 0 anfängt; bei einem Array der Größe
n ist der maximale Index n-1. Wenn wir ein Array mit kleinstem
Index l haben wollen, muss man den Zugriff etwas abwandeln:
A k l - cells + \ und jetzt @ oder ! B k l - + \ und jetzt c@ oder c!Dabei wird nicht überprüft, ob der Index im vorgesehenen Bereich ist; das muss der Programmierer auf andere Weise sicherstellen. Versäumnisse in dieser Hinsicht sind eine häufige Fehlerquelle und auch eine häufige Sicherheitslücke (insbesondere buffer overflow attack). Höherlevelige Programmiersprachen wie Java überprüfen allerdings den Index beim Arrayzugriff, ein Zugriff ausserhalb des Arrays kann daher dort nicht vorkommen.
32 constant hl \ lower index
127 constant hu \ upper index+1
here hu hl - cells allot constant hist
: inc { addr -- }
addr @ 1 + addr ! ;
: count-char { c -- }
c hl >= if
c hu < if
hist c hl - cells + inc
endif
endif ;
: show-hist ( -- )
hu hl ?do
cr hist i hl - cells + @ .
i emit
loop ;
: count-chars { addr u -- }
addr u + addr ?do
i c@ count-char
loop ;
: char-hist { addr u -- }
hist hu hl - cells erase \ hist loeschen
addr u count-chars
show-hist ;
Dabei gibt emit ( c -- ) einen Wert als (ASCII-)Zeichen aus.
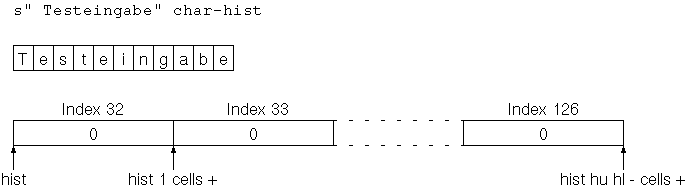
Wir können dieses Programm mit einer Eingabe wie
s" Testeingabe" char-histtesten, wobei
S" den Text bis zum " als
Zeichen-Array (String) abspeichert und die Adresse und Länge des
Arrays ( addr u ) auf den Stack legt. Dieses Array, und
das Array hist sind in folgender Grafik dargestellt:
Als interessantere Eingabe kann man eine ganze Datei verwenden:
s" slides.tex" slurp-file char-hist
slurp-file ( addr1 u1 -- addr2 u2 ) liest den Inhalt der
Datei mit dem durch addr1 u1 angegebenen Namen als großes
Zeichen-Array in den Speicher und legt die Anfangsadresse und Länge
des Arrays auf den Stack.
In obiger Version von count-chars werden die
Start-Adresse und die End-Adresse als Schleifenparameter verwendet,
und i liefert in jeder Iteration die Adresse eines Bytes.
Man kann aber auch einfach von 0 bis zur Länge des Arrays hochzählen,
und die Adressberechnung erst unmittelbar vor dem c@
machen:
: count-chars { addr u -- }
u 0 ?do
addr i + c@ count-char
loop ;
Wir können jetzt auch das Problem der Ausgabe der Ziffern einer Zahl in der richtigen Reihenfolge lösen:
20 constant d-len
here d-len allot constant d
: digits ( n -- )
d d-len + 1-
begin { n d1 }
n while
n 10 mod '0 + d1 c!
n 10 / d1 1 -
repeat
d1 d d-len + d1 - type ;
type ( addr u -- ) gibt einen String
aus. '0 produziert den ASCII-Code von 0.
Die Ziffern 0..9 folgen im ASCII-Code unmittelbar aufeinander, sodass
man für einen Zahlenwert <10 einfach den ASCII-Code von 0
dazuzählen kann und den ASCII-Code der entsprechenden Ziffer erhält.
Das kann man sich auch in Forth veranschaulichen:
: print-ascii ( u l -- )
?do
i emit
loop ;
'9 1 + '0 print-ascii
Bei digits wird das Array vom Ende her gefüllt, damit die
Zeichen danach in der richtigen Reihenfole für type im
Speicher stehen.
Allgemein werden Dateien verwendet, um Daten über eine Sitzung hinweg zu speichern, und um Daten von einem Programm zum anderen zu übertragen; für Datentausch sind Dateien nicht die einzige Möglichkeit, aber eine sehr gebräuchliche.
Eine Text-Datei enthält nur die einzelnen Zeichen und einige ASCII-Kontrollzeichen wie CR (ASCII 13), LF (10), oder beides für das Zeilenende und TAB (9) für die Einrückung. Text-Dateien können mit vielen Werkzeugen relativ einfach verarbeitet werden, und sind deshalb die gebräuchliche Form, Quellcode abzuspeichern, quer über alle Programmiersprachen.
Text-Dateien werden mit einem Text-Editor geschrieben und bearbeitet. Die meisten Programmierer finden irgendwann einmal ihren Lieblings-Editor, und bleiben dem dann dauerhaft treu.
Ein Unterschied zu einem Textverarbeitungsprogramm ist, dass man
bei der Textverarbeitung das Aussehen des Textes (z.B. Schrift-Art,
Schriftgröße, Dicke, Schrägstellung) bestimmen kann; das muss
mitabgespeichert werden, und daher sind die Dateien, die ein Dokument
einer Textverarbeitung speichern, im Normalfall keine Text-Dateien im
oben genannten Sinn; sie sind normalerweise auch spezifisch für das
Textverarbeitungsprogramm und können nur von wenigen anderen
Programmen bearbeitet werden, wenn überhaupt. Man kann sich den
Unterschied auch leicht anschauen, wenn man einen kurzen Text mit
einem Text-Editor schreibt und mit einer Textverarbeitung, und sich
dann die Dateigrößen anschaut, und z.B. mit einem Dump-Programm wie
z.B. hd den Inhalt der Dateien.
Viele Editoren bieten spezielle Unterstützung für die Programmierung, zum Beispiel Einfärben gewisser Elemente (syntax colouring) oder Unterstützung bei der Einrückung. Manche Editoren erlauben den Aufruf des Compilers oder Programmiersystems, oder anderer Werkzeuge, z.B. Debugger. Das führt dann zu Integrierten Entwicklungsumgebungen (integrated developmentenvironments, IDEs) wie z.B. Eclipse.
Wenn Sie mit einem Editor eine Datei datei.fs erstellt
haben, können Sie sie mit
gforth datei.fsausführen. Wenn Sie dabei gleich einen Aufruf machen wollen, den Sie nicht in die Datei hineinschreiben wollen, können Sie den Aufruf auch auf die Kommandozeile schreiben:
gforth char-hist.fs -e 's" slides.tex" slurp-file char-hist bye'Hier sorgt das abschliessende
bye dafür, dass Gforth am
Ende verlassen wird, Gforth wird also in diesem Beispiel als
Script-Sprache eingesetzt.
Zunächst ist zu bemerken, dass das Histogramm-Programm nicht als eine große Definition geschrieben wurde, sondern im mehreren kleineren. Diese kann man dann einzeln testen, und so schon den Fehler eingrenzen, und eventuell doch durch Inspektion finden.
Wenn das mit der Inspektion des Quellcodes nicht wirkt, ist es oft erhellend, zu sehen, was zur Laufzeit passiert. Viele Entwicklungsumgebungen bieten dazu die Möglichkeit, das Programm schrittweise durchzugehen (single-step debugging), und bei jedem Schritt die Daten zu inspizieren.
Auch Gforth bietet diese Möglichkeit, dazu muss man es allerdings
mit gforth-itc starten, statt mit gforth.
Um ein Wort im Single-Step-Modus auszuführen, rufen Sie es
mit dbg wort auf. Z.B.:
s" I will never do anything bad ever again" dbg char-histDabei gibt es in jedem Schritt eine Zeile wie
7FFFF6A4F998 60FFD0 >l -> [ 1 ] 6640464oder
7FFFF6A4F9E0 60FB30 cells -> [ 2 ] 140737331393488 00760Zunächst gibt der Debugger zum
-> aus, dann wartet er
auf eine Eingabe des Benutzers, dann führt er den Schritt aus, und
zeigt das Ergebnis des Schritts auf dem Stack an (die Tiefe des
Stacks, und die Werte auf dem Stack als Zahlen in der aktuellen
Basis).
An der dritten Stelle steht das Wort, das in diesem Schritt ausgeführt
wurde, z.B. cells oder >l.
Wobei >l nicht im Quelcode vorkommt, sondern aus der
Definition der Locals stammt; an der ersten Stelle ist die Adresse des
Codes, der in diesem Schritt ausgeführt wurde, und an zweiter Stelle
der Inhalt der Zelle an dieser Stelle, beides als Hex-Zahl. Das Wort
an dritter Stelle ist eine Interpretation dieser Daten als
Forth-Quellcode, was allerdings z.B. bei Locals nicht so recht gelingt.
Ähnliche Einschränkungen gibt es auch in anderen Umgebungen. Z.B. zeigt gdb bei optimierten C-Programmen zwar Quellcode an, der wird aber dann nicht in der erwarteten Reihenfolge durchschritten, und die Werte von Variablen stimmen dabei oft nicht mit dem überein, was man sich von einer schrittweisen Ausführung des Originalcodes erwarten würde, da die Optimierung z.B. die Reihenfolge von Operationen geändert hat.
Als Befehle ist für uns besonders die Enter-Taste interessant. Sie
führt das Wort komplett aus. Weiters ist auch noch die
Taste n interessant: wenn man sie bei einer Definition
anwendet, führt der Debugger die Definition schrittweise aus. (Wenn
man n bei einem nicht in Forth definierten Wort verwendet,
z.B. >l, zeigt der Debugger den Maschinencode für das
Wort an, oder versucht es zumindest.
Leider ist auf manchen Systemen das installierte Gforth nicht mit dem installierten gdb (der zum Disassemblieren des Maschinencodes verwendet wird) kompatibel, sodass das System dann hängt und nur durch Abschiessen das gdb-Prozesses (z.B. unter Linux mit "killall gdb") zum Weiterarbeiten bewegt werden kann. Sie können die Ausgabe des Disassemblers aber mit
' dump is discode ' 2drop is discodeaber auf einen Speicherdump reduzieren oder ganz weglassen.
Das schrittweise Ausführen eines Programmes kann zwar hilfreich sein, um zu verstehen, wie Programme ausgeführt werden, ist bei tausenden, Millionen, Milliarden oder Billionen Schritten, die Programme typischerweise ausführen, als Debuggingtechnik nicht sehr effektiv; insbesondere wenn man sich bei jedem Schritt noch überlegen muss, ob das Ergebnis jetzt stimmt oder nicht.
Debugger bieten daher Möglichkeiten an, Schritte zu überspringen, auch der Gforth-Single-Step-Debugger.
Nach meiner Erfahrung ist aber auch das nicht besonders effektiv, weil man zu leicht in Versuchung gerät, einfach weiter im Einzelschrittmodus weiterzumachen, statt sich sinnvolle Abkürzungen zu überlegen. Das ist umso verführerischer, weil man traditionellerweise nicht mehr so einfach zurückgehen kann, wenn man einmal zuviel abgekürzt hat.
Dann wäre es schön, das Programm bis zur Fehlermeldung auszführen, und sich dann anzuschauen, welche Werte im Speicher oder am Stack falsch sind, und dann per Rückwärts-Watchpoints die Plätze im Programm zu finden zu finden, wo diese falschen Werte herkommen; wenn die aus anderen, schon falschen Werten berechnet wurden, wiederholt man das ganze für die anderen Wert, ansonsten hat man die Fehlerquelle gefunden (wenn es sich, wie meistens, um einen einfachen Fehler handelt).
Leider ist Rückwärts-Debugging in der Form noch nicht in Gforth implementiert.
Diese Prüfung kann über automatisch überprüfbare Zusicherungen (Assertions) erfolgen. Wenn wir zum Beispiel überprüfen wollen, dass wir bei den Zugriffen auf hist nicht ausserhalb des reservierten Speicherbereichs zugreifen, können wir das wie folgt machen:
: check-in-hist { addr -- addr }
assert( addr hist hist hu hl - cells + within )
addr ;
Dabei muss der Code zwischen assert( und )
eine Zelle auf den Stack legen, die "falsch" (also 0) sein soll, wenn
die Zusicherung nicht erfüllt ist. within ( x1 x2 x3 -- f
) überprüft x2≤x1<x3.
Und dieses Wort check-in-hist können wir dann vor
dem inc in count-char und vor
dem @ in show-hist einfügen.
Assertions fügt man meist schon beim Codieren ein, nicht erst beim Debuggen. Und zwar fügt man sie ein, wenn man so eine automatische Prüfung hinschreiben kann, und wenn man der Quelle der Daten nicht besonders traut, zum Beispiel weil sie aus kniffligem Code kommen, bei dem die Fehlerhäufigkeit meist hoch ist, oder weil das Programmstück von irgendwoher aufgerufen werden kann. Besonders gerne verwendet man daher Assertions, um die Vorbedingungen eines Wortes zu prüfen, soweit möglich.
Neben diesen automatisch prüfbaren Zusicherungen gibt es auch noch Zusicherungen zu Dokumentationszwecken, die als Kommentare hingeschrieben werden. Zum Beispiel sind die Schleifeninvarianten bei unseren fac-Beispielen solche Zusicherungen: Das Überprüfen dieser Invarianten benötigt ein funktionierendes Fac-Wort, sodass es normalerweise unpraktikabel ist, das automatisch zu überprüfen.
Die Vorbedingung der Fac-Wörter könnte man dagegen mit automatisch geprüften assertions prüfen.
Wenn man einmal genug Vertrauen in die Korrektheit des Programmes hat, kann man das Überprüfen der Assertions auch abdrehen, wenn diese Überprüfung zuviel Zeit kostet. In Gforth geht das mit
0 assert-level !vor dem Code, in dem man die Assertions abdrehen will, und
1 assert-level !danach.
show-hist einfügt):
hist.fs:6: failed assertion :1: assertion failed s" bla " >>>char-hist<<< Backtrace: $7FFC4734C988 throw $7FFC47373CC8 c(abort") $7FFC4739F738 (end-assert) $7FFC4739F978 check-in-hist $5F $7F $7FFC4739FAD0 show-histHier sieht man, dass es auf der Kommandozeilenebene ein Fehler in
char-hist passiert ist (das ja direkt von der
Kommandozeile aufgerufen wurde), dieses rief
dann show-hist auf, und das
dann check-in-hist (dazwischen werden noch zwei Zahlen
angezeigt, die vom ?do
stammen. Check-in-hist ruft (end-assert)
auf (Laufzeit-Code, der von assert(...) erzeugt wurde),
und das wiederum c(abort")
und throw.
printf()
heisst.
Diese Debuggingmethode hat einige Vorteile:
." und .s. Aber es gibt in Gforth
noch das Wort ~~ (``Tracer'') für diesen Zweck. Es zeigt
an, wo es im Code steht, und was auf dem Stack ist. Wenn wir
z.B. unser fac-Beispiel damit verzieren
: fac { n -- n! }
n
n 1 ?do ~~ ( n1 )
i ~~ *
loop ;
5 fac .
erhalten wir folgende Ausgabe:
fac.fs:3:<1> 5 fac.fs:4:<2> 5 1 fac.fs:3:<1> 5 fac.fs:4:<2> 5 2 fac.fs:3:<1> 10 fac.fs:4:<2> 10 3 fac.fs:3:<1> 30 fac.fs:4:<2> 30 4 120Hier wird die Position des ausgebenden Tracers immer über den Dateinamen und die Zeile angezeigt (sodass wir verschiedene Tracer unterscheiden können; besonders hilfreich im Zusammenspiel mit Editoren wie Emacs), und den Stack-Inhalt.
Solche Ausgabebefehle platziert man oft unmittelbar hinter einem Kontrollfluss-Wort, um dem Kontrollfluss folgen zu können, oder dort, wo interessante Daten berechnet wurden (und im Falle von Forth besonders gerne dort, wo sie auf dem Stack sind).
Ein häufiges Problem dabei ist, dass man den Fehler falsch behebt, dass die Änderung zwar für eine richtige Behandlung des bisher fehlgeschlagenen Testfall sorgen, aber das Programm dafür in anderen Fällen jetzt ein falsches Ergebnis liefert. Daher sollte man für ein Programm eine Menge von Tests haben (eine Testsuite), die man nach jeder Änderung erneut testet. Solche Tests nennt man Regressionstests, da sie Testen, was in dem Programm schon funktioniert hat; wenn sie nicht mehr funktionieren, ist das ein Rückschritt, also eine Regression. Mit einer guten Testsuite kann man dadurch so einen Fehler finden.
Weiters fügt man einen Testfall oder mehrere zu den Regressionstests dazu, die den Fehler aufdecken würden. Es passiert nämlich doch recht oft, dass ein Fehler zurückkommt, und dann würde man ihn durch diese Testfälle sofort bemerken.
Schon einmal gemachte Fehler sind deswegen häufiger als irgendwelche anderen Fehler, weil viele Fehler nicht zufällig passieren, sondern weil der Teil des Programms, in dem sie vorkommen, besonders schwierig ist, und die für dieses Problem naheliegende (Schein-)Lösung falsch ist.
Zum Beispiel kann es passieren, dass man die Fehlerbehebung trotz der Regressionstests einen Fehler hinterlassen hat, der aber erst nach längerer Zeit auffällt. Und wenn man diesen Fehler dann beheben will, kann es vorkommen, dass man die ursprungliche fehlerhafte Lösung wieder einbaut (weil sich der ursprüngliche Programmierer nicht mehr an den Fehler in dieser Lösung erinnert, oder ein anderer Programmiere diesen Fehler bearbeitet). Dann dienen die Regressionstests als institutionelles Gedächtnis.
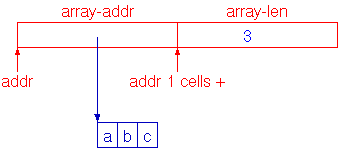
So ein Verbund von Daten wird (nach den Namen in verschiedenen Programmiersprachen) Record oder Struktur genannt, eine Verallgemeinerung davon (auf die wir später eingehen werden) sind Objekte bzw. Klassen. Die Einzelteile eines Records heißen Felder (bzw. bei Objekten Instanzvariablen oder Objektvariablen).
Im Bild oben ist der Record im Speicher in rot dargestellt, in blau die enthaltenen Daten (die Adresse und die Länge eines Strings), und der String (Byte-Array) selbst.
Wie im Bild zu sehen, implementieren wir Records, indem wir die einzelnen Felder hintereinander im Speicher anordnen. Der Unterschied zum Array liegt in der Verwendung, nicht in der Implementierung. Wir könnten jetzt z.B. wir folgt auf die Struktur zugreifen:
: array@ { addr1 -- addr2 u }
addr1 @
addr1 1 cells + @ ;
: array! { addr2 u addr1 -- }
addr2 addr1 !
u addr1 1 cells + ! ;
Bei größeren Programmen, in denen verschiedene Records im Spiel sind,
wird es allerdings bald schwer durchschaubar, ob 1 cells
+ der Zugriff auf das Längenfeld des Array-Deskriptors ist,
oder etwas anderes. Daher ist es sinnvoll, Worte für diese Felder
einzuführen:
: array-addr ( addr1 -- addr2 )
;
: array-len ( addr1 -- addr2 )
1 cells + ;
: array@ { addr1 -- addr2 u }
addr1 array-addr @
addr1 array-len @ ;
: array! { addr2 u addr1 -- }
addr2 addr1 array-addr !
u addr1 array-len ! ;
Neben der Dokumentationswirkung hat die Verwendung
von array-addr und array-len noch weitere
Vorteile: Da die konkrete Anordnung der Felder jetzt nur mehr in
diesen Wörtern präsent ist statt im ganzen Programm, könnte man die
Anordnung der Felder bei Bedarf mit wenig Aufwand ändern.
[Das ist nur ein Beispiel für ein allgemeines Prinzip: Da immer wieder alle möglichen Änderungen in Programmen vorkommen, ist es hilfreich, Implementierungsentscheidungen an einer Stelle zu konzentrieren, damit man bei Bedarf nur diese Stelle ändern muss statt das ganze Programm.]
Da man öfters solche Wörter für Feldzugriffe braucht, gibt es schon eigene Definitionswörter dafür in Gforth. Z.B. können wir unseren Array-Deskriptor wie folgt definieren:
struct cell% field array-addr cell% field array-len end-struct array-desc%Zusätzlich definiert dieser Code das Wort
array-desc%,
das wir zum Beispiel verwenden können, um einen Array-Deskriptor als
Feld in einem anderen Record zu definieren, oder (wie wir später sehen
werden), um Speicher für den Record zu reservieren.
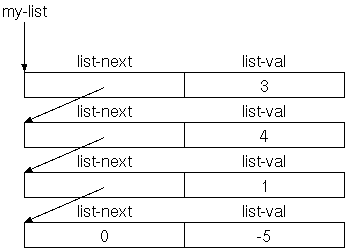
Die oben gezeigte verkettete Liste besteht aus vier gleichen
Records mit je zwei Feldern: Das erste Feld ist die Adresse des
nächsten Records in der Liste (das nächste Listenelement), das zweite
Feld enthält die Nutzdaten, in unserem Fall (der Einfachkeit halber)
eine ganze Zahl. Wenn es kein nächstes Listenelement gibt), speichern
wir 0 in das Feld list-next.
Bei solchen Datenstrukturen, bei denen Records die Adressen anderer Records enthalten, die Records also aufeinander zeigen, nennt man die Records auch Knoten (node) und die Adressen/Zeiger auch (gerichtete) Kanten (edge), abgeleitet von der Graphentheorie in der Mathematik; diese Datenstrukturen kann man nämlich auch als gerichtete Graphen sehen.
Hier die Definition der Listenrecords:
struct cell% field list-next cell% field list-val end-struct list%Wir können ein Listen-Element wie folgt erzeugen:
: new-list { list1 val -- list2 }
list% %allot { list2 }
list1 list2 list-next !
val list2 list-val !
list2 ;
Wobei %allot ( record-desc -- addr ) Platz für den Record
im Dictionary reserviert und die Anfangsadresse des reservierten
Platzes auf den Stack legt.
Mit new-list können wir die oben gezeigte Liste wie
folgt aufbauen:
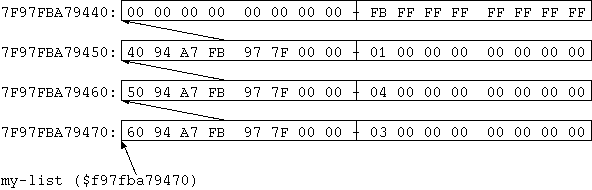
0 -5 new-list 1 new-list 4 new-list 3 new-list constant my-listMan kann sich die Liste jetzt im Speicher anschauen:
my-list hex. $7F97FBA79470 ok my-list 6 cells - 8 cells dump 7F97FBA79440: 00 00 00 00 00 00 00 00 - FB FF FF FF FF FF FF FF ................ 7F97FBA79450: 40 94 A7 FB 97 7F 00 00 - 01 00 00 00 00 00 00 00 @............... 7F97FBA79460: 50 94 A7 FB 97 7F 00 00 - 04 00 00 00 00 00 00 00 P............... 7F97FBA79470: 60 94 A7 FB 97 7F 00 00 - 03 00 00 00 00 00 00 00 `...............[
my-list zeigt auf den Anfang des letzten Records, davor sind drei
andere mit jeweils zwei Zellen, insgesamt sind 4 Records à 2 Zellen
vorhanden.]
Mit folgendem Wort können wir die Elemente der Liste ausgeben:
: .list ( list -- )
begin { l }
l while
l list-val @ .
l list-next @
repeat ;
my-list .list
Im obigen Beispiel wurde eine Liste direkt gebaut, mit dem letzten
Element beginnend, und das Ergebnis haben wir uns dann in einer
Konstante gemerkt. Wenn wir in eine Liste nachträglich ein Element
einfügen wollen, ist die Konstante zum merken nicht sehr praktisch.
Stattdessen können wir uns eine Zelle im Speicher reservieren und die
Liste dort abspeichern:
here 1 cells allot constant lp my-list lp !Jetzt zeigt
lp auf die Zelle, in der die Adresse des
ersten Records der Liste steht. Wir können jetzt ein weiteres Element
vorne in diese Liste einfügen:
lp @ 7 new-list lp ! lp @ .listDa wir das vielleicht oefters machen möchten, machen wir eine Definition dafür:
: insert { val listp -- }
listp @ val new-list listp ! ;
9 lp insert
lp @ .list
Einfügen am Ende ist etwas komplizierter, weil wir zuerst das Ende
suchen müssen:
: insert-end { val listp -- }
listp begin { lp1 }
lp1 @ while
lp1 @ list-next
repeat
0 val new-list lp1 ! ;
11 lp insert-end
lp @ .list
Bemerkenswert ist hier: Wir brauchen die Adresse (nicht den Inhalt)
der Zelle, in der die abschließende 0 gespeichert ist, damit wir dort
das Element anhängen können. Diese Möglichkeit, mit Referenzen auf
Speicherstellen umzugehen, gibt es in einer Reihe von
Programmiersprachen, aber nicht in Java. Wir werden später sehen, wie
wir dieses Problem in Java umschiffen.
Bemerkung: Wenn man öfters am Ende einfügen will, kann man sich auch die Adresse der Zelle mit der abschließenden 0 merken, zusätzlich zu der Adresse der Zelle, in der das erste Element steht.
Wie können wir alle Werte einer Liste aufaddieren?
: sum-list { list -- n }
0 list begin { l } ( n1 )
l while
l list-val @ +
l list-next @
repeat ;
lp @ sum-list .
Wenn wir uns sum-list anschauen, sehen wir große
Ähnlichkeiten zu .list; im Schleifenkörper ist
jetzt + statt ., aber sonst ist alles gleich
(abgesehen vom Stack-Bild-Kommentar). Tatsächlich werden alle Wörter,
die die Liste von vorne nach hinten durchgehen und mit jedem Element
etwas, machen, so ausschauen. Wir können diese Gemeinsamkeit auch in
ein eigenes Wort faktorisieren:
: do-list ( x1 list xt -- x2 ) { xt }
begin { l } ( x )
l while
l list-val @ xt execute
l list-next @
repeat ;
: .list ( list -- )
['] . do-list ;
: sum-list { list -- n }
0 list ['] + do-list ;
lp @ .list
lp @ sum-list .
Wir übergeben an do-list nicht nur die Liste, sondern
auch ein Wort, repräsentiert durch die Anfangsadresse dieses Wortes;
diese Adresse heißt in Forth Execution token oder kurz xt. Dieses xt
wird dann in der Schleife mit execute ( ... xt -- ... )
ausgeführt. Das Execution Token eines Wortes erhält man innerhalb
einer Definition mit ['] wort und ausserhalb
mit ' wort. D.h, ausserhalb einer Definition
ist 3 ' . execute das gleiche wie 3 ..
Wir können mit do-list auch noch weitere Dinge tun, z.B. das
Maximum der Listen-Elemente berechnen:
-$80000000 lp @ ' max do-list .
Damit die Stack-Tiefe im Schleifenrumpf gleich bleibt, muss das von
xt repräsentierte Wort eine Zelle mehr vom Stack nehmen als es auf den
Stack legt. Der bei do-list angegebene Stack-Effekt und
die Stack-Bilder ist für den Fall geschrieben, dass man das xt eines
Wortes mit dem Stack-Effekt ( x1 x2 -- x3 ) übergibt
(z.B. + oder max), aber man sieht
am .list-Beispiel, dass auch der Stack-Effekt ( x2 -- )
möglich ist; der Stack-Effekt von do-list ist dann ( list
xt -- ).
exitwhile zu berücksichtigen. Eine andere Möglichkeit
ist es, die ganze Definition bei Erreichen einer der
Abbruchbedingungen zu verlassen (die andere Abbruchbedingung wird
weiterhin mit while abgefangen). Zum Verlassen der
Definition gibt es das Wort exit.
Als Beispiel suchen wir in unserer Liste von Zahlen nach einer konkreten Zahl:
: member? { key liste -- flag }
liste begin { l }
l while
l list-val @ key = if
true exit endif
l list-next @
repeat
false ;
Hier verwenden wir dieselbe Struktur wie bei den bisherigen Schleifen
über Listen, das while bricht also ab, wenn das Ende der
Liste erreicht ist. Für den Abbruch beim Finden des gesuchten Wertes
verwenden wir ein exit in
einem if...endif. Dabei muss man beachten,
dass die Stack-Effekte bei beiden Möglichkeiten, die Definition zu
verlassen, zusammenpassen müssen.
Auch wenn die Struktur dieses Wortes durchaus in
das do-list-Schema zu passen scheint, kann man hier
do-list nicht verwenden: Man müsste key = if true
exit endif in eine eigene Definition auslagern, aber da würde
das exit nur diese Definition verlassen, nicht
aber do-list.
Wenn man exit in ?do...loop
einsetzt, muss man vor dem exit noch unloop
schreiben.
Übung: Schreiben Sie ein Wort, das in einem Array nach einem bestimmten Element sucht.
+ - * / < .
+ - * u< u.
+ - @ ! (zweiter Parameter)
! (erster Parameter)
+ - c@ c! (zweiter Parameter)
emit c! (erster Parameter)
execute
Diese Sicht, Datentypen über die Wörter bzw. Operationen zu definieren, die auf ihnen arbeiten, nennt man strukturelle Typisierung oder auch duck typing (abgeleitet von dem Satz: "When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck").
Wobei Zahlen, Adressen, Flags, und Execution Tokens auch Zellen sind
und damit ebenfalls als erster Parameter in ! vorkommen
dürfen. Man spricht davon, dass Zahlen, Adressen, Flags und Execution
Tokens Untertypen des Typs Zelle sind. Wenn man ein Wort
geschrieben hat, das für Zellen im Allgemeinen arbeitet, funktioniert
es für alle Arten von Zellen, ob es jetzt eine Zahl ist oder eine
Adresse (Ersetzbarkeitsprinzip). Wir werden Untertypen und
Ersetzbarkeit später genauer betrachten.
Bei den Adressen von Zellen ist es oft sinnvoll, noch weiter zu
unterscheiden (also Untertypen des Typs "Adresse von Zelle" zu
verwenden). Zum Beispiel übergibt man list-next die
Adresse eines Listenknoten und erhält die Adresse einer Zelle, in der
0 oder die Adresse eines Listenknoten steht; und während
man .list die Adresse eines Listenknoten (oder 0)
übergibt, ist das zweite Argument bei insert
und insert-end die Adresse einer Zelle, in der 0 oder die
Adresse eines Listenknoten steht.
Wenn man ein Wort auf ein Datum vom falschen Typ anwendet, wird das Programm nicht das gewünschte Ergebnis liefern; so etwas ist ein Typfehler. In vielen Programmiersprachen werden Typfehler vom Compiler (statische Typüberprüfung) oder zur Laufzeit (dynamische Typüberprüfung) erkannt und gemeldet, in Forth nicht.
In Forth liegt es am Programmierer, Typfehler zu vermeiden. Dazu werden in den Stack-Bildern und Stack-Effekt-Kommentaren die Stack-Elemente auch entsprechend den Typen benannt. Für einfache Typen wie vorzeichenbehaftete bzw. vorzeichenlose ganze Zahlen gibt es da Konventionen ("n" bzw. "u"), bei komplizierteren Typen muss man sich selbst welche setzten; z.B. steht bei den Listenwörtern oben "list" für die Adresse eines Listenknotens (oder 0) und "listp" (für list pointer) für die Adresse einer Zelle, in der 0 oder die Adresse eines Listenknoten steht.
Die Typen der Zellen auf dem Stack sind also eine statische Eigenschaft, genau wie die Stacktiefe. Allerdings hat man es nicht nur im Stack mit Typen zu tun, sondern auch im Speicher.
Einige Wörter funktionieren auf mehreren Typen,
z.B. funktioniert + für vorzeichenlose und
vorzeichenbehaftete Zahlen, und um Adressen und Zahlen zu addieren.
Das liegt aber nur daran, dass Adressen auch Zahlen sind, und dass die
Repräsentation der vorzeichenbehafteten Zahlen genau so gewählt wurde,
dass die vorzeichenlose Addition auch für vorzeichenbehaftete Zahlen
funktioniert.
Im allgemeinen funktioniert ein Wort aber nur für einen Typ. Z.B. haben wir verschiedene Wörter für die Ausgabe:
.list ein Wort, das spezifisch für
vorzeichenbehaftete ganze Zahlen ist, nämlich . (weiters
verwendet sum-list das Wort +, das z.B. nicht
sinnvoll auf execution tokens angewendet werden kann).
Für die meisten Wörter (list-next list-val new-list insert
insert-end do-list) spielt es aber keine Rolle, welcher
Untertyp von Zellen als Nutzlast gespeichert ist (eine Zelle muss es
aber sein). Man kann diese Wörter daher allgemeiner benutzen als
ursprünglich vorgesehen, nämlich für alle Listen mit Zellen als
Nutzlast. Diese Listen sind funktionieren also generisch für Zellen
und alle Untertypen von Zelle. Diese Eigenschaft nennt man daher
Generizität.
Wenn man allerdings z.B. .list auf einer Liste, die
mit diesen Wörtern erstellt wurde, anwenden will, muss man die Liste
schon mit vorzeichenbehafteten ganzen Zahlen als Nutzlast erstellen.
Das Wort do-list selbst ist zwar generisch, aber der
xt-Parameter muss mit dem Typ der Elemente zusammenpassen: Wenn man
ein Wort übergibt, das auf dem Top-of-Stack einen Typ T erwartet, dann
dürfen nur Elemente vom Typ T als Nutzlast vorkommen. Ein Beispiel
ist die Implementierung von .list
mit do-list: Hier wird als xt ein Wort übergeben, das
vorzeichenbehaftete ganze Zahlen erwartet, also kann man auch diese
Implementierung von .list nur für Listen von solchen
Zahlen verwenden. Wenn man mit Hilfe von do-list für
vorzeichenlose ganze Zahlen ausgeben will, muss man
entsprechend ['] u. übergeben. Auch
mit do-list kann man aber nur Listen von Elementen
desselben Typs ausgeben.
Es ist nicht einfach, Generizität in Programmiersprachen mit statischer Typprüfung zu integrieren. Zum Beispiel wurde sie erst 9 Jahre nach der Entwicklung von Java zu Java hinzugefügt. Deswegen wird diese Eigenschaft Programmiersprachen mit statischer Typprüfung besonders erwähnt; sie braucht dort auch eigene Sprachkonstrukte.
Wenn ein Programm mit verschiedenen Typen umgehen kann, nennt man das Polymorphismus. Generizität ist eine (von zwei) Hauptformen davon, und man nennt sie auch parametriscen Polymorphismus.
struct cell% field obj-print \ xt ( obj -- ) end-struct obj% obj% cell% field signed-val end-struct signed% obj% cell% field person-svnum \ 64 bits nötig bei einfacher Speicherung cell% field person-name-addr cell% field person-name-len end-struct person%Die Strukturdefinitionen von
signed%
und person% fangen nicht mir einer leeren Struktur an,
sondern setzen dort fort, wo die Definition von object%
aufhört. Das Feld obj-print wird von der elterlichen
Struktur obj% geerbt, und hat bei beiden Typen den selben
Offset. Man kann also bei beiden Typen auf dieses Feld zugreifen,
ohne zu wissen, welcher der beiden Typen es jetzt konkret ist.
Mit folgenden Wörtern können wir ein Record signed%
und ein Record person% ausgeben:
: .signed ( signed -- )
signed-val @ . ;
: .person { person -- }
person person-name-addr @ person person-name-len @ type
." SV-Nummer:" person person-svnum @ u. ;
Wie gehabt kann man .signed sinnvollerweise nur
auf signed%-Records anwenden, und .person
nur auf person%-Records. Definieren wir noch
Konstruktoren dazu:
: new-signed { n -- signed }
signed% %allot { signed }
['] .signed signed obj-print !
n signed signed-val !
signed ;
: new-person { svnum name-addr name-len -- person }
person% %allot { person }
['] .person person obj-print !
svnum person person-svnum !
name-addr person person-name-addr !
name-len person person-name-len !
person ;
5 new-signed constant signed1
1234567890 s" Jane Doe" new-person constant person1
In den Konstruktoren wird auch noch das Feld obj-print
gesetzt, und zwar bei signeds auf das xt von .signed und
bei persons auf das xt von .person. Das kann man dzu
verwenden, um ein Ausgabe-Wort zu schreiben, das für beide Typen
funktioniert:
: .obj { obj -- }
obj obj obj-print @ execute ;
signed1 .obj
person1 .obj
Hier weiss .obj zwar nichts über den konkreten Typ des
Parameters obj, aber es weiss, dass es ein Feld obj-print
hat, und dass dort das xt eines Wortes steht, das den konkreten Typ
richtig ausgeben kann. Es führt dann dieses Wort aus, und dieses Wort
weiss dann auch, welchen konkreten Typ der Parameter
hat: .obj führt .signed nur aus, wenn das
Record tatsächlich ein signed%-Record ist, denn nur dann
steht in obj-print das xt von .signed.
Entsprechend für den Fall, wenn man .obj
ein person%-Record übergibt.
Übung: Definieren Sie ein Record unsigned%, das
von obj% erbt, ein dazugehöriges Ausgabewort, und einen
dazugehörigen Konstruktor.
Obwohl man im allgemeinen (z.B. bei .objarray unten)
den konkreten Typ des Parameters von .obj nicht kennt,
weiss man also, sobald die Ausführung ein konkretes Ausgabewort
(z.B. .person) erreicht hat, den konkreten Typ des
Parameters (z.B. person). Man hat also in .person wieder
statisches Typ-Wissen.
Da man .obj auch mit signeds und persons verwenden
kann, sind das Untertypen von obj. Da .obj mit
verschiedenen konkreten Typen umgehen kann, ist es ein polymorphes
Wort. Diese Art des Polymorphismus nennt
man Untertyp-Polymorphismus und er ist die Basis für
objektorientierte Programmiersprachen.
Typen, die als einzige Operation die Ausgabe zulassen, sind zwar nicht besonders aufregend, aber das ist ein einfaches Beispiel dafür, wie die objektorientierten Konzepte wie Klassen, Objekte, und dynamische Bindung implementiert sind, die wir später kennenlernen.
Wir können jetzt Objekte mit verschiedenen konkreten Typen in einem Array (oder auch einer Liste) speichern und abarbeiten.
here 3 cells allot constant a
signed1 a 0 cells + !
person1 a 1 cells + !
9 new-signed a 2 cells + !
: .objarray { addr len -- }
len 0 ?do
cr addr i cells + @ .obj
loop ;
a 3 .objarray
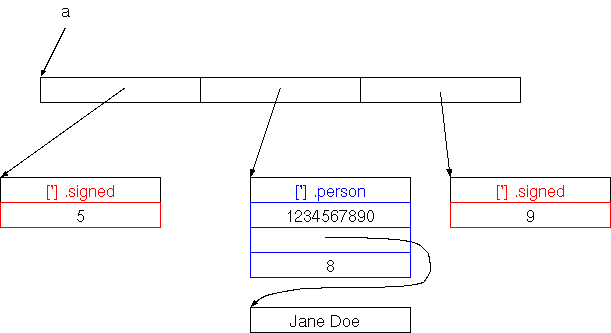
Wir können auch einen weiteren Objekt-Typ erzeugen, indem wir von einem existierenden erben:
person%
cell% field student-matnr
end-struct student%
: .student { s -- }
s .person
." Mat-Nr.: " s student-matnr @ . ;
: new-student { svnum name-addr name-len matnr -- student }
student% %allot { s }
['] .student s obj-print !
svnum s person-svnum !
name-addr s person-name-addr !
name-len s person-name-len !
matnr s student-matnr !
s ;
9876543210 s" John Smith" 1499999 new-student constant student1
student1 .student
student1 .person
student1 .obj
student1 a 2 cells + !
a 3 .objarray
0 5 new-list constant list1 list1 constant list2Dabei legen
list1 und list2 die gleiche
Adresse auf den Stack. Wir können weitere Records mit dem
gleichen Inhalt erstellen:
0 5 new-list constant list3Dieses Record hat zwar den selben Inhalt, aber eine andere Adresse:
list1 .list cr list1 . list2 .list cr list2 . list3 .list cr list3 .

Solange man die Records nicht verändert, spielt das keine Rolle, aber wenn man sie verändert, schon:
6 list1 list-val ! list2 .list list3 .listDas an der von list1 angegebenen Adresse wird geändert; wenn man auf eine andere Art auf dieselbe Adresse zugreift, sieht man die Änderung auch. Das Objekt, auf das list3 zeigt, wird dagegen nicht verändert.
Als nächstes hängen wir ein Element vorne in der Liste ein:
list1 8 new-list constant list4 list1 .list list2 .list list3 .list list4 .list
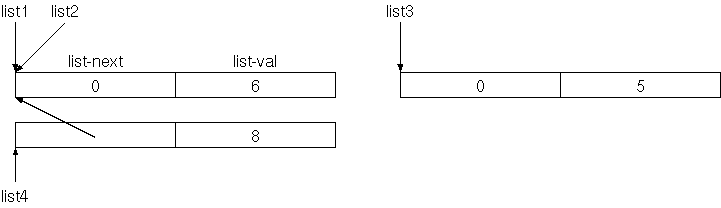
Wie man sieht, hat das an list1, list2, und list3 nichts geändert.
Der Konstruktor new-list hat also
keine Seiteneffekte
auf existierende Listen und ihre Referenzen. Im Gegensatz dazu hat
ein Wort wie insert-end Seiteneffekte auf existierende
Listen:
cell% %allot constant listp1 list4 listp1 ! 9 listp1 insert-end list1 .list list2 .list list3 .list list4 .list
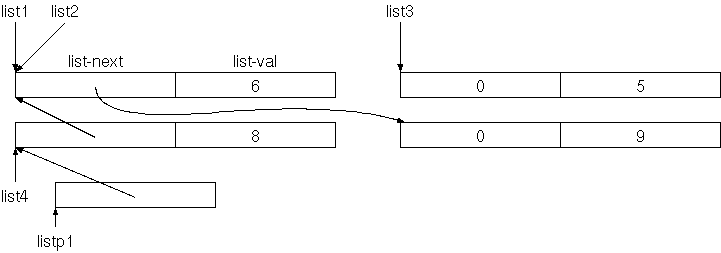
In imperativen Sprachen wie Forth und Java verzichtet man normalerweise nicht auf die Verwendung von Seiteneffekten, und muss daher genau über die Objektidentität bescheid wissen. Insbesondere muss man zwischen dem Objekt und einer Referenz darauf unterscheiden. Der Unterschied ist bei manchen Programmiersprachen nicht so offensichtlich, z.B. in Java; aber wenn man weiss, dass man darauf achten muss, sind die entsprechenden Hinweise in der Dokumentation durchaus vorhanden.
Wenn man Wörter mit Seiteneffekten auf eine Datenstruktur anwenden
will, aber nicht will, dass der Seiteneffekt für andere Benutzer der
Datenstruktur sichtbar wird, muss man Teile oder die ganze
Datenstruktur kopieren, und dann das Wort mit dem Seiteneffekt auf die
Kopie anwenden. Z.B. muss man dann für insert-end die
gesamte Liste kopieren, da der Seiteneffekt auf den letzten Record
wirkt; wenn man nur den Wert im ersten Record ändern will, muss man
nur diesen Knoten kopieren:
: copy-node { list1 -- list2 }
list1 list-next @ list1 list-val @ new-list ;
list4 copy-node constant list5
2 list5 list-val !
list4 .list
listp @ .list
list5 .list
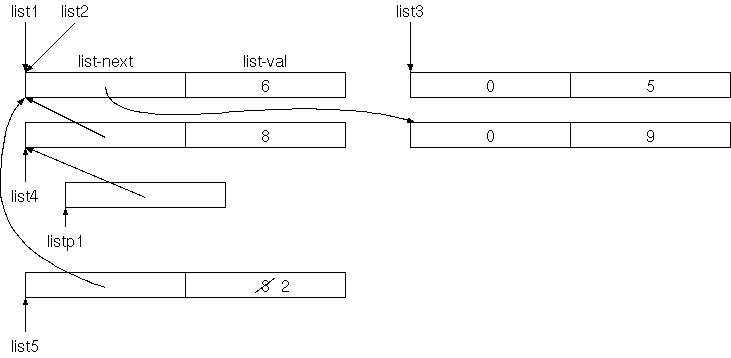
Man kann auf alle diese Überlegungen verzichten, wenn man auf Seiteneffekte verzichtet. Dann muss man das, was man sonst mit Seiteneffekten macht, aber auf andere Art machen. Diese Techniken lernen Sie im Rahmen der funktionalen Programmierung und der Logik-Programmierung, denn die entsprechenden Programmiersprachen erlauben keine Seiteneffekte (oder wenn, dann nur sehr eingeschränkt).
allot
und %allot aus dem Dictionary reserviert. Von dort holt
man sich normalweise Speicher, den man bis zum Ende des Programmlaufs
nicht mehr freigibt. Klassischerweise hat man damit Speicher für ein
paar Arrays reserviert, und dann mit diesen Arrays gearbeitet; solche
Programme haben zur Laufzeit keinen weiteren Speicher benötigt. Das
ganze nennt man auch statische Speicherallokation.
Allerdings sind die Möglichkeiten, so zu programmieren, recht
eingeschränkt. Man kann zum Beispiel zur Laufzeit keinen Speicher für
Listenknoten reservieren. Wir können das in Forth zwar
mit allot machen, aber das ist dann zwar keine statische
Allokation mehr; was wichtiger ist, im Allgemeinen wird dadurch
irgendwann der Speicher ausgehen, auch wenn die meisten der
Listenelemente nicht mehr in Verwendung sind und keine Referenzen auf
diese Listenknoten mehr existieren.
Daher wurde eine dynamische Speicherverwaltung entwickelt, bei der
man Speicher reservieren und reservierten Speicher wieder freigeben
konnte; in Forth mit den Wörtern allocate
und free, in C mit malloc()
und free(). Dieses Konzept führt allerdings zu Fehlern:
Man kann Speicher freigeben, auf den noch Referenzen in Verwendung
sind (dangling reference, ein Spezialfall davon ist ein
"double free"-Fehler), oder Speicher nicht freigeben, obwohl er nicht
mehr verwendet wird (Speicherleck, memory leak bei
langlaufenden Programmen).
In höherleveligen Sprachen wie Java übernimmt daher die Laufzeitumgebung die Freigabe des Speichers, auf den es keine Referenzen mehr gibt (Garbage Collection). Es kann allerdings in manchen Fällen hilfreich sein, unbenutzte Referenzen zu löschen; dann kann das Laufzeitsystem den Speicher der Datenstruktur früher freigeben.
javac ListNode.java java ListNode gforth ListNode.fsausführen.
public class ListNode {
// struct
public int val; // cell% field list-next
public ListNode next; // cell% field list-val
// end-struct list%
In Java verwendet man dieselbe Syntax zum Definieren von Feldern (auch
Objektvariablen oder Instanzvariablen genannt) wie
für lokale Variablen; der Unterschied ist, dass lokale Variablen in
einer Methode stehen, und Felder direkt in einer Klasse.
Da die Klasse definiert, welche Felder zu einem Record zusammengefasst werden, braucht man für jeden Recordtyp, den man definieren will, eine eigene Klasse.
ListNode(int v, ListNode l) { // : new-list { list1 val -- list2 }
val = v; // list% %allot { list2 }
next = l; // list1 list2 list-next !
} // val list2 list-val !
// list2 ;
Das ist ein Konstruktor, erkennbar daran, dass er den selben Namen hat
wie die Klasse (und die Definitionssyntax unterscheidet sich ein
bisschen von normalen Methoden). Der Aufruf dieses Konstruktors
erflogt z.B. mit new ListNode(5, null). Dabei erhält
dann die lokale Variable v den Wert 5 und die lokale Variable l den
Wert null.
Die Speicherreservierung erfolgt in Forth explizit, in Java
implizit; der Konstruktor dient nur dazu, nach der
Speicherreservierung die Felder zu initialisieren. Auf die Felder
kann man direkt mit dem Namen zugreifen, oder, wenn der Name
z.B. durch eine gleichnamige lokale Variable verdeckt ist,
mit this.name.
static void print(ListNode l) { // : .list ( list -- )
while (l != null) { // begin { l }
System.out.print(l.val); // l while
System.out.print(" "); // l list-val @ .
l = l.next; // l list-next @
} // repeat ;
System.out.println();
}
Statische Methoden werden mit static definiert; die
(dynamischen) Methoden (ohne static lernen wir später
kennen. Wir sehen hier allerdings den Aufruf von zwei
nicht-statischen Methoden: System.out.print(int i)
und System.out.print(String s); und zwar ruft man diese
Methoden für das Objekt System.out auf; sie unterscheiden
sich durch den Typ des Parameters.
void ist der Rückgabetyp der Methode, und bedeutet,
dass sie nichts zurückgibt.
Die von uns definierte Methode heißt print, genau wie
zwei der Methoden, die in dieser Methode aufgerufen werden. Allgemein
erlaubt Java die vielfältige Verwendung des gleichen Namens, wobei
dann bei Verwendung verschiedene Möglichkeiten genutzt werden, um
diese Mehrfachdefinition aufzulösen. Der Typ der Argumente ist einer
davon; in Forth hat man diese Möglichkeit nicht, und verwendet lieber
verschiedene Namen.
Die Methode hat einen Parameter l vom Typ ListNode.
Parameter sind Variablen, die in den Klammern einer Methodendefinition
stehen, und sie werden mit dem Wert initialisiert, der an dieser
Stelle als Argument übergeben wird.
Die Methode enthält eine Schleife, um alle Listenelemente auszugeben. Ein Unterschied zwischen den Schleifen der beiden Sprachen ist, wie der Wert von l geändert wird: In Forth wird er am Anfang der Schleife aus dem definiert, was am Stack ist, und am Ende der Schleife wird der nächste Wert auf den Stack gelegt. In Java wird am Ende der Schleife der neue Wert berechnet und in die Variable l gespeichert.
static void almostInsertEnd(int v, // : insert-end { val listp -- }
ListNode l) {// listp begin { lp1 }
while (l.next != null) // lp1 @ while
l=l.next; // lp1 @ list-next
l.next = new ListNode(v, null); // repeat
} // 0 val new-list lp1 ! ;
Da man in Java keine Referenzen auf Speicherstellen zur Verfügung hat,
können wir die auch nicht an InsertEnd übergeben. Daher machen wir
vorerst eine Variante, die versagt, wenn man eine leere Liste als
Parameter übergibt. Statt (in Forth) eine Referenz auf die
Speicherstelle, die den nächsten Listenknoten enthält, merken wir uns
in Java den vorigen Listenknoten. Wir werden später noch andere
Lösungen dieses Problems betrachten.
Sobald ein Knoten mit einem leeren next-Feld gefunden ist, wird ein neuer Listenknoten erzeugt, und die Referenz in diesem Feld gespeichert.
static ListNode copy(ListNode l) { // : copy-node { list1 -- list2 }
return new ListNode(l.val, l.next); // list1 list-next @
} // list1 list-val @ new-list ;
Hier ist der Rückgabewert eine Referenz auf ein ListNode-Objekt. Die
Java-Methode entspricht direkt der Forth-Definition.
Wer schon mehr Java-Erfahrung hat, wird sich vielleicht fragen, warum ich hier nicht clone() definiere und weiter unten verwende. Der Grund liegt daran, dass ein ordentliches clone eine komplette Kopie der gesamten Liste machen sollte, und nicht nur des ersten Knotens.
public static void main(String [] args) {
ListNode list1=new ListNode(5, null); // 0 5 new-list constant list1
ListNode list2=list1; // list1 constant list2
ListNode list3=new ListNode(5,null); // 0 5 new-list constant list3
print(list1); // cr list1 .list
print(list2); // cr list2 .list
print(list3); // cr list3 .list
In Java wird beim Aufruf java ListNode die
Methode main der Klasse ListNode aufgerufen;
wenn man also will, dass etwas passiert, muss man es dorthin
schreiben, oder dort zumindest die Aufrufe der Methoden, in denen es
passiert.
Hier enthält main die Java-Version unseres Testcodes
für die Objektidentität. Nach diesen Aufrufen ist der Zustand wie
folgt:
In Java wird also mit new ein Objekt angelegt, und
Variablen, die einen Objekttyp haben, enthalten immer nur Referenzen
auf die entsprechenden Objekte. Wir haben hier also zwei Objekte und
drei Variablen mit Referenzen darauf.
list1.val=6; // 6 list1 list-val !
System.out.println(); // cr
print(list1); // cr list1 .list
print(list2); // cr list2 .list
print(list3); // cr list3 .list
Hier zeigt sich in der Ausgabe, dass list1 und list2 Referenzen auf
das selbe Objekt sind. Bei beiden wird die Liste "6" augegeben, bei list3 "5".
ListNode list4=new ListNode(8, list1); // list1 8 new-list constant list4
System.out.println(); // cr
print(list1); // cr list1 .list
print(list2); // cr list2 .list
print(list3); // cr list3 .list
print(list4); // cr list4 .list
// cell% %allot constant listp1
// list4 listp1 !
almostInsertEnd(9, list4); // 9 listp1 insert-end
System.out.println(); // cr
print(list1); // cr list1 .list
print(list2); // cr list2 .list
print(list3); // cr list3 .list
print(list4); // cr list4 .list
Da man in Java keine Referenzen auf Speicherstellen schreiben kann,
wird hier auch keine Speicherstelle dafuer angelegt und initialisiert.
Da list4 aber nicht leer ist, macht der Aufruf
von almostInsertEnd hier das gleiche wie der
von insert-end (bei der Java-Variante die listp1-Zelle
wegdenken):
ListNode list5=copy(list4); // list4 copy-node constant list5
System.out.println(); // cr
print(list1); // cr list1 .list
print(list2); // cr list2 .list
print(list3); // cr list3 .list
print(list4); // cr list4 .list
print(list5); // cr list5 .list
list5.val=2; // 2 list5 list-val !
System.out.println(); // cr
print(list1); // cr list1 .list
print(list2); // cr list2 .list
print(list3); // cr list3 .list
print(list4); // cr list4 .list
print(list5); // cr list5 .list
} // cr bye
}
Hier wird der Knoten, auf den list4 zeigt, kopiert, und das Ergebnis
merken wir uns in list5. Durch Ändern von list5.val und
die Ausgabe der Listen, auf die unsere Referenzen zeigen, sehen wir,
dass list5 nicht auf das selbe Objekt zeigt wie list4.
list-next machen wir hier dieses Feld an zweiter
Stelle. Wir beginnen mit einer Liste mit zwei Knoten:
cell% %allot constant listp 0 3 new-list 1 new-list listp ! listp @ .list
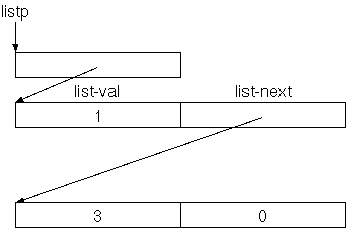
Betrachten wir als einfachen Fall einmal das Einfügen eines Knotens
mit dem Wert 5 zwischen erstem und zweitem Knoten. Wir müssen
zunächst den neuen Knoten anlegen. Das Feld list-val
dieses Knotens setzen wir auf 5; list-next des neuen
Knoten soll auf den letzten Knoten der Liste zeigen:
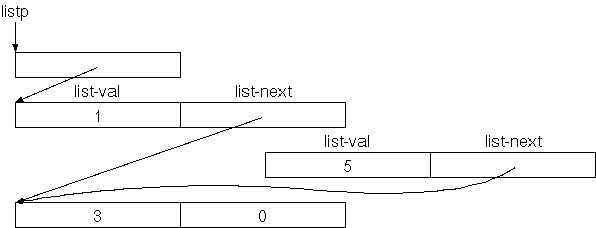
Im letzten Schritt überschreiben wir die Zelle die bisher auf das letzte Listenelement zeigt mit der Adresse des neuen Listenelements:
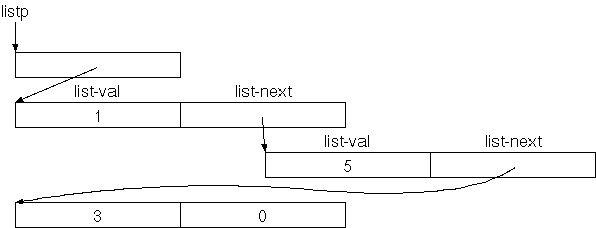
Damit das funktioniert, muss unserem Einfügewort die Adresse der
Zelle list-next übergeben werden, bzw. allgemein die
Adresse einer Zelle, in der der Zeiger auf den Listenknoten steht, vor
dem das neue Element eingefügt werden soll.
5 listp @ list-next insert listp @ .listWenn wir nach dem ersten Element einer Liste irgendwo ein Element einfügen wollen, ist der zweite Parameter von
insert die
Adresse des Feldes list-next des Knoten, hinter dem wir
einfügen wollen. Wenn wir vor dem ersten Knoten einfügen wollen,
übergeben wir die Zelle, in der die Adresse auf den ersten Knoten
steht, in unserem Beispiel also listp.
7 listp insert listp @ .list
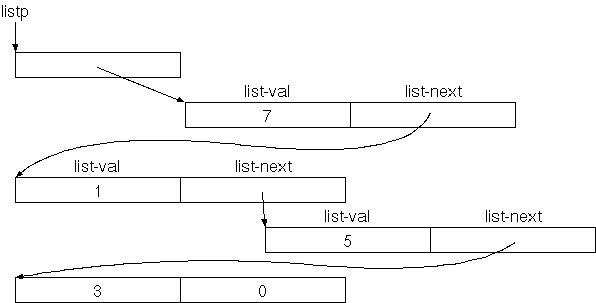 Diese Zelle haben wir genau dafür angelegt.
Diese Zelle haben wir genau dafür angelegt.
member?.
: search { key listp -- listp2 } \ : member? { key liste -- flag }
listp begin { lp } \ liste begin { l }
lp @ while \ l while
lp @ list-val @ key = if \ l list-val @ key = if
lp exit endif \ true exit endif
lp @ list-next \ l list-next @
repeat \ repeat
lp ; \ false ;
Search muss ja immer die Adresse der Zelle, die auf das
gerade betrachtete Element zeigt, bereithalten (als lp),
damit es diese Adresse an den Aufrufer zurückgeben kann, wenn es
fertig ist.
Der interessanteste Unterschied daraus ergibt sich bei der
Berechnung des Wertes für die nächste Iteration: lp @
list-next bei search, l list-next @ bei member?.
Wenn wir diese Berechnungen verschiedener Iterationen aneinandergereit
sehen (als Trace ohne die Abbruchbedingungen) und das Definieren und
Benutzen der lokalen Variablen weglassen, sehen wir in beiden Fällen
eine Sequenz ... @ list-next @ list-next .... Der
Unterschied zwischen den beiden Schleifen ist, wo der Rest der
Schleife eingefügt wird: bei search zwischen list-next
und @, bei member? zwischen @
und list-next.
Die Unterschiede bei den Abbruchbedingungen kommen daher, dass man
in beiden Fällen die Adresse des Knotens braucht, dafür bei search
aber lp @ statt l schreiben muss. Und die
Rückgabewerte sind verschieden und dementsprechend auch der Code
dafür.
Hier eine Verwendung von search. Wir wollen einen Knoten mit dem Wert 8 von dem Knoten mit dem Wert 5 einfügen.
8 5 listp search insert cr listp @ .listDer Forth-Code für dieses Beispiel ist in dieser Datei.
almostInsertEnd beschritten.
Allerings gibt es am Anfang der Liste keinen Vorgängerknoten. Unsere erste Lösung behandelt diesen Fall als Sonderfall:
public class List1 {
ListNode head;
Zunächst brauchen wir eine eigene Klasse für unsere Liste: Wir
brauchen ein Feld head mit einer Referenz auf den ersten
Listenknoten, und wir müssen dieses Feld in ein Objekt packen (und
dafür eine Klasse definieren), damit wir eine Referenz darauf machen
können, die wir dann unserer Einfügemethode übergeben können; denn
diese Methode soll ja head verändern können.
Wir definieren keinen Konstruktor für List1, und das System initialisiert dieses Feld daher mit null, also einer leeren Liste (Vorsicht, in manchen Programmiersprachen gibt es so eine automatische Initialisierung nicht, da würde eine fehlende Initialisierung wahrscheinlich zu einem Fehler führen).
static void searchInsert(List1 l, int key, int v) {
// neuen Knoten mit Wert v vor dem Knoten mit wert key in l einfuegen
// bzw. am Ende
ListNode previous = null;
ListNode n = l.head;
while (n != null && n.val != key) {
previous = n;
n = n.next;
}
ListNode newnode = new ListNode(v, n);
if (previous == null) {
l.head = newnode;
} else {
previous.next = newnode;
}
}
Da wir keine Referenzen auf Speicherstellen übergeben können wie in
Forth, haben wir hier die beiden Wöerter search und insert zu einer
Methode searchInsert zusammengefasst. Der Nachteil dabei
ist, dass man den search-Teil nicht wiederverwenden kann, wenn man zum
Beispiel ein searchDelete schreiben will.
Wir verwenden zwei Variablen: n zeigt auf den Knoten, den wir gerade untersuchen, und previous auf den vorherigen Knoten; wenn es keinen vorherigen Knoten gibt, also in der ersten Iteration, ist previous gleich null. Eine Schleifeninvariante ist also
((previous==null && n==l.head) || previous.next==n)Wenn die Schleife verlassen wurde, möchten wir das neue Element zwischen previous und n einfügen. Dazu bauen wir uns einmal den neuen Knoten mit n als Nachfolgeknoten. Die Referenz auf diesen neuen Knoten wollen wir also dem next-Feld des previous-Knotens zuweisen, und wenn previous!=null, dann machen wir das auch.
Das geht aber nicht, wenn die Schleife schon bei der ersten Iteration abgebrochen hat. Das erkennen wir daran, dass previous noch gleich null ist. In dem Fall hängen wir das neue Element direkt im head ein. head entspricht also in der Forth-Version der Zelle, auf die listp zeigt.
Bemerkung zu Syntax und Semantik von Java: "==" ist der Vergleich auf Gleichheit, "!=" auf Ungleichheit, "&&" ist ein logisches und, und "||" ist ein logisches oder. "=" ist die Zuweisung des Wertes auf der rechten Seite an die Variable oder das Feld auf der linken Seite.
Bei n != null && n.val != key sehen wir auch
die Kurzschlussauswertung
(short-circuit evaluation) beim Operator &&: Zuerst
wird n!=null ausgewertet; wenn das Ergebnis falsch ist,
wird der zweite Teilausdruck gar nicht mehr ausgewertet und das
Ergebnis des gesamten Ausdrucks ist falsch. Ansonsten ist das
Ergebnis des zweiten Teilausdrucks das Ergebnis des Gesamtausdrucks.
Dass der zweite Teilausdruck nicht mehr ausgewertet wird, wenn n==null
ist, ist deswegen wichtig, weil n.val dann einen Fehler liefern würde.
Bei || ist es ähnlich, nur ist der Ausdruck wahr, wenn schon der erste Teilausdruck wahr ist, und dementsprechend wird dann der zweite Teilausdruck nicht mehr ausgewertet.
public static void main(String [] args) {
List1 l1=new List1();
l1.head = new ListNode(1, new ListNode(3,null));
ListNode.print(l1.head);
searchInsert(l1, 3, 5);
ListNode.print(l1.head);
searchInsert(l1, 1, 7);
ListNode.print(l1.head);
searchInsert(l1, 5, 8);
ListNode.print(l1.head);
// Einfuegen am Ende testen
searchInsert(l1, 99, 9);
ListNode.print(l1.head);
}
}
In unserer Hauptmethode bauen wir einfach (wie in der Forth-Version)
eine Liste mit zwei Knoten mit den Werten 1 und 3, und fügen dann vor
dem Knoten 3 einen weiteren Knoten 5 ein, vor dem Knoten 1 einen
Knoten 7 (dabei wird getestet, ob das Einfügen am Anfang
funktioniert), usw. Das Einfügen vor dem Knoten 99 testet, ob auf der
Fall funktioniert, wo der Wert nicht gefunden wird und am Ende
eingefügt werden soll.
Das Java-Programm finden Sie in diesem Verzeichnis, Sie benötigen die Dateien List1.java und ListNode.java.
Es gibt auch noch eine andere Möglichkeit, das Problem am Anfang der Liste anzugehen: Wir sorgen dafür, dass es auch für den ersten richtigen Knoten einen Vorgängerknoten gibt, der allerdings nur für diesen Zweck da ist. Die Nutzlast dieses Knotens spielt in diesem Vorgängerknoten keine Rolle:
public class List2 {
ListNode prehead;
List2() {
prehead = new ListNode(0,null);
}
Dieser Vorgängerknoten des ersten Knotens wird im Feld prehead unseres
List2-Objektes gespeichert, und wir erzeugen im Konstruktor von List2
diesen Knoten und weisen die Referenz auf diesen Knoten prehead zu.
static void searchInsert(List2 l, int key, int v) {
// neuen Knoten mit Wert v vor dem Knoten mit wert key in l einfuegen
// bzw. am Ende
ListNode previous = l.prehead;
ListNode n = previous.next;
while (n != null && n.val != key) {
previous = n;
n = n.next;
}
ListNode newnode = new ListNode(v, n);
previous.next = newnode;
}
Hier können wir jetzt previous mit der Referenz auf den prehead-Knoten
initialisieren, und brauchen am Ende der Schleife keinen Sonderfall
mehr behandeln: previous zeigt immer auf den Knoten, in dessen
next-Feld wir einfügen wollen. Die obige Schleifeninvariante ist auch
einfacher, der Sonderfall ist weg:
previous.next==nDie Main-Methode ist zwar im Grunde gleich wie bei List1, aber die Verwendungen von
head mussten
durch prehead.next ersetzt werden:
public static void main(String [] args) {
List2 l1=new List2();
l1.prehead.next = new ListNode(1, new ListNode(3,null));
ListNode.print(l1.prehead.next);
searchInsert(l1, 3, 5);
ListNode.print(l1.prehead.next);
searchInsert(l1, 1, 7);
ListNode.print(l1.prehead.next);
searchInsert(l1, 5, 8);
ListNode.print(l1.prehead.next);
// Einfuegen am Ende testen
searchInsert(l1, 99, 9);
ListNode.print(l1.prehead.next);
}
Grundsätzlich löst man das Problem, indem man von der konkreten Implementierung abstrahiert und abstrakte Schnittstellen in Form von Methoden zur Verfügung stellt.
In unserem Fall könnte man z.B. eine Methode print(List1) bzw. print(List2) zur Verfügung stellen, und einen Konstruktor, der einen ListNode als Parameter nimmt. Dann wären die Zugriffe auf head bzw. prehead auf diese Methoden beschränkt und main() und andere Aufrufer würden diesen Unterschied nicht sehen. Siehe List1a.java und List2a.java; beachten Sie die kaum vorhandenen Unterschiede bei main().
Eine andere Alternative wäre es, zwei Methoden
void setHead(List1 l, ListNode n); ListNode getHead(List1 l);zur Verfügung zu stellen, sogenannte getter und setter-Methoden. Mit diesen könnte man zwar in unserem Fall das Problem lösen, allerdings ist der Abstraktionsgrad relativ gering und oft zu gering; zum Beispiel kann man einen getter und setter fuer prehead von List2 nicht so einfach in List1 implementieren.
Man sollte sich also sinnvolle Abstraktionen überlegen, und da die richtigen zu finden, ist eine Kunst, und man wird die optimalen Schnittstellen meist nicht im ersten Versuch finden.
Damit ein Programmierer, die eine Klasse verwendet, nicht doch auf
die Interna der Implementierung zugreift und dann sein Programm bei
Änderung der Implementierung nicht mehr funktioniert, schränkt man den
Zugriff auf die Interna ein (data hiding, infomation hiding). In Java
kann man zum Beispiel die Sichtbarkeit von Feldern und Methoden
mit private einschränken.
Allerdings kann man nicht alle gewünschten Einschränkungen mit Sprachfeatures ausdrücken. In unserem Beispiel ist main() ja eine Methode von List1 bzw. List2 und kann auch auf head bzw. prehead zugreifen, wenn diese private sind. Viele Einschränkungen kann man nur über die Dokumentation mitteilen. Umgekehrt sollten Sie bei Verwendung einer Klasse solche Einschränkungen in der Dokumentation beachten, das erhöht die Chance, dass Ihr Programm noch mit der nächsten Version der Klasse läuft.
Wichtige Begriffe in diesem Zusammenhang sind Schnittstelle (Interface; es gibt auch ein Java-Sprachfeature, das so heisst, hier ist aber ein allgemeineres Konzept gemeint), die beschreibt, wie auf eine Komponente (z.B. eine Klasse) von anderen Komponenten zugegriffen werden kann. Dadurch müssen sich die Verwender der Komponente nicht mi der Implementierung beschäftigen, sondern nur mit der Schnittstelle (die meistens deutlich einfacher ist); umgekehrt hat man beim Implementieren der Komponente gewisse Freiheiten, weil man sich nur an die Schnittstelle halten muss.
Das ganze geht von einer Rollenverteilung von Verwender und Implementierer einer Komponente aus, und ist besonders wichtig, wenn das verschiedene Personen sind. Aber es hilft auch, wenn es dieselbe Person ist. Hätte ich beim Schreiben von List1 schon von den Zugriffen auf head abstrahiert, hätte ich beim Schreiben von List2 wenig an main ändern müssen.
public abstract class Obj { // struct
public abstract void print(); // cell% field obj-print \ xt ( obj -- )
} // end-struct obj%
//
// : .obj { obj -- }
// obj obj obj-print @ execute ;
Eine Klasse (class) beschreibt eine bestimmte Art von Objekten. Diese
Objekte werden dann Instanzen (instances; die korrekte deutsche
Übersetzung wäre "Exemplar", aber "Instanz" hat sich durchgesetzt)
genannt. Eine Klasse wäre zum Beispiel "Person", Instanzen davon
"Jane Doe" und "John Smith".
In Java legen Sie meist für jede Klasse eine neue Datei an, und umgekehrt müssen Sie in einer Datei eine Klasse definieren.
Hier definieren wir eine Klasse Obj (die Forth-Entsprechung
ist obj%), mit einer Methode print()
(entsprechend .obj). Die Klasse ist abstract, das heißt,
man darf von dieser Klasse keine Instanzen erzeugen; sie dient nur als
Fundament für Unterklassen.
Und die Methode print() ist ebenfalls abstract, das heisst, es gibt
keine konkrete Implementierung für diese Klasse, und auch print() wird
nur in Unterklassen implementiert; die Deklaration von print() hier
dient dazu, um die Schnittstelle der Klasse Obj und (vor allem) ihrer
Unterklassen festzulegen. Wenn ich zum Beispiel eine
Methode foo(Obj x) schreibe, weiss ich, dass ich x mit
der Methode print() ausgeben kann.
Im Gegensatz zu allen bisherigen Methoden ist print() nicht
statisch (kein static-Keyword bei der Deklaration). Was
das genau bedeutet, sehen wir weiter unten.
In Java muss man kein Feld obj-print definieren. Intern macht Java
so etwas ähnliches, weil print() keine statische Methode ist, aber das
sieht man als Programmierer nicht. Umgekehrt kann man so etwas in
Java gar nicht explizit schreiben, weil es so etwas wie Execution
Tokens und execute in Java nicht direkt gibt.
public class Signed extends Obj { // obj%
int val; // cell% field signed-val
Signed(int n) { // end-struct signed%
val=n; //
} // : .signed ( signed -- )
static public void print(Signed s) {// signed-val @ . ;
System.out.print(s.val); //
} // : new-signed { n -- signed }
public final void printSigned() { // signed% %allot { signed }
System.out.print(val); // ['] .signed signed obj-print !
} // n signed signed-val !
public void print() { // signed ;
// System.out.print(val);
// printSigned();
print(this);
}
}
Signed ist eine Unterklasse von Obj (angezeigt durch extends
Obj). Wir fügen ein Feld val hinzu. Jede Instanz der Klasse
hat also so ein Feld.
Der Konstruktor Signed(int n) initialisiert das Feld. Man erzeugt
sich ein Objekt und ruft diesen Konstruktor auf, indem man
z.B. new Signed(5) schreibt. Das Anlegen des Objektes
und die Verwaltung der internen Informationen geschieht automatisch,
der Konstruktor initialisiert nur noch die Felder; in unserem Fall
entspricht also das, was der Konstruktor zu tun hat, dem n
signed signed-val ! in Forth, der Rest wird automatisch vom
System gemacht.
Danach sehen wir noch drei Varianten von Ausgabemethoden:
Zunächst eine statische Methode print(Signed s)
(entsprechend .signed). Dieser Methode übergibt man das
auszugebende Objekt beim Aufruf in den Klammern
(z.B. print(s1)), und wir erhalten dieses Argument dann
als Parameter s, und greifen über s auf dieses Objekt zu.
Danach kommen zwei nicht-statische Methoden printSigned() und
print(). Die nicht-statischen Methoden (meist auch einfach "Methoden"
genannt) werden z.B. mit s1.print() aufgerufen; in der
Methode kann man auf das Objekt vor dem Punkt mit this
zugreifen, und auf das Feld val mit this.val oder einfach mit val.
print() ist die Implementierung der abstrakten Methode print() aus der Klasse Obj für die (konkrete) Klasse Signed. Wir sehen hier drei mögliche Implementierungen, zwei davon in Kommentaren: Die nicht auskommentierte Version ruft einfach das statische print(Signed s) auf, und zwar mit dem Objekt this als Parameter. Ein Aufruf s1.print() bewirkt also dann einen Aufruf print(s1).
Eine Alternative wäre es, den Wert direkt auszugeben
mit System.out.print(val). Dabei sieht man einen Zugriff
auf das Feld val von this.
Als weitere Alternative sehen wir einen Aufruf der nicht-statischen
Methode printSigned(). Wir könnten das mit this.printSigned() machen,
aber in dem meisten Fällen kann man "this." weglassen. Nur wenn es
mögliche Namenskonflikte gibt, braucht man "this." eventuell, um sie
zu vermeiden. Das final gibt an, dass man printSigned()
in Unterklassen nicht überschreiben (override) kann. Näheres dazu
später.
Die Forth-Variante entspricht am ehesten der nicht-auskommentierten: .signed entspricht einer statischen Methode, und .obj ruft diese auf, wenn das Objekt ein signed% ist, und die Verbindung wird über das Feld obj-print hergestellt, indem es mit dem xt von .signed initialiert wird. In Java müssen wir das nicht hinschreiben, dafür müssen wir eben diese Definition von print() hinschreiben, und das System macht die Details automatisch.
public class Person extends Obj { //obj%
long svnum; // cell% field person-svnum
String name; // cell% field person-name-addr
Person(long svnum, String name) { // cell% field person-name-len
this.svnum=svnum; //end-struct person%
this.name=name; //
} //: .person { person -- }
public static void print(Person p) // person person-name-addr @
{ // person person-name-len @ type
System.out.print(p.name); // ." SV-Nummer:"
System.out.print(" SV-Nummer:");// person person-svnum @ u. ;
System.out.print(p.svnum); //
} //: new-person
public final void printPerson() // { svnum name-addr name-len -- person }
{ // person% %allot { person }
System.out.print(name); // ['] .person person obj-print !
System.out.print(" SV-Nummer:");// svnum person person-svnum !
System.out.print(svnum); // name-addr person person-name-addr !
} // name-len person person-name-len !
public void print() // person ;
{
print(this);
}
}
Vom Aufbau und von den verwendeten Mechanismen her ist die Klasse
Person der Klasse Signed sehr ähnlich. Beides sind Unterklassen von
Obj. Der größte Unterschied liegt darin, dass es hier zwei Felder
gibt, und eines davon ein String ist.
Beim Konstruktor sehen wir hier (im Gegensatz zu Signed) den Fall, dass die lokalen Variablen svnum und name die selben Namen haben wie die Felder svnum und name. Wenn man nur den Namen angibt, bezieht sich das dann immer auf die lokale Variable (bzw. allgemein auf den Namen, der weiter innen in der Verschachtelung definiert ist). Um auf die Felder zugreifen zu können, schreiben wir this.svnum und this.name; dann ist klar, dass sich das auf die entsprechenden Felder von this bezieht.
Die folgende Klasse kam in der Vorlesung vom 26.5. noch nicht vor, die Klasse Main weiter unten aber teilweise schon.
public class Student extends Person { //person%
int matnr; // cell% field student-matnr
Student(long svnum, String name, //end-struct student%
int matnr) { //
super(svnum,name); //: .student { s -- }
this.matnr=matnr; // s .person
} // ." Mat-Nr.: " s student-matnr @ . ;
public static void print(Student s)//
{ //: new-student { sv n-addr n-len mat -- s }
Person.print(s); // student% %allot { s }
System.out.print(" Mat-Nr.:"); // ['] .student s obj-print !
System.out.print(s.matnr); // sv s person-svnum !
} // n-addr s person-name-addr !
public final void printStudent() // n-len s person-name-len !
{ // mat s student-matnr !
printPerson(); // s ;
System.out.print(" Mat-Nr.:");
System.out.print(matnr);
}
public void print()
{
this.printStudent();
}
}
Die Klasse Student ist eine Unterklasse der Klasse Person (und damit
indirekt auch von Obj, aber diesmal nicht direkt); man sagt dazu auch
Kindklasse. Daher hat ein Objekt der Klasse Student alle Felder und
Methoden von Person. Dazu kommt dann noch das Feld matnr.
Beim Konstruktor Student könnte man hier alle drei Felder explizit initialisieren, aber wir machen es anders: Wir rufen mit super(svnum,name) den Konstruktor für die Oberklasse auf. Wenn die Felder der Oberklasse private sind, dann kann man in der Unterklasse nicht darauf zugreifen, und dann ist das der naheliegendste Weg, sie zu initialisieren. Zusätzlich initialisiert der Konstruktor auch das zusätzliche Feld matnr. (In der Forth-Variante werden alle Felder direkt initialisiert).
Das statische print(Student s) ruft das statische print(Person s) der Klasse Person auf, um die Felder auszugeben, die jede Person (und daher auch ein Student) hat, und gibt das zusätzliche Feld selbst aus. Da ein Student ein Untertyp von Person ist, kann man s als Parameter an die Methode Person.print(Person) übergeben, obwohl diese Methode eine Person als Parameter erwartet.
printStudent() ist eine Methode ähnlich printPerson(), also nicht-statisch, aber final. printStudent() gibt die Felder aus, die alle Personen haben, indem es printPerson() aufruft. Der Student, den printStudent() ausgeben soll (in der Variable this) wird automatisch an printPerson() weitergereicht, und wird dort dessen this. Man könnte das auch explizit machen, indem man this.printPerson() hinschreibt. Zusätzlich gibt printStudent() die Matrikelnummer aus, wie gehabt.
Die Methode print() ist die Implementierung der abstrakten Methode print() der Klasse Obj für die Klasse Student. Im Gegensatz dazu sind die statischen Methoden Signed.print(Signed), Person.print(Person), und Student.print(Student) alles unterschiedliche Methoden, und printSigned(), printPerson(), printStudent() natürlich auch. Statische Methoden in unterschiedlichen Klassen sind grundsätzlich verschieden (auch wenn sie den selben Namen haben), und nichtstatische Methoden mit unterschiedlichen Namen auch. Die Methode print() ist aber nichtstatisch und hat den selben Namen (und die selben Parameter) in allen von Obj abgeleiteten Klassen, und es handelt sich dabei also um verschiedene Implementierungen der selben abstrakten Methode.
Hier ist print() einfach als Aufruf von printStudent() implementiert, diesmal mit explizitem this.
public class Main {
static void printArray(Obj a[]) { //: .objarray { addr len -- }
for (int i=0; i<a.length; i++) { // len 0 ?do
a[i].print(); // cr addr i cells + @ .obj
System.out.println(); // loop ;
}
}
In der Klasse Main definieren wir eine statische Methode printArray(Obj a[]), die als Parameter ein Array a von Obj-Referenzen hat; dass es sich um ein Array handelt, sieht man an "[]". printArray() ruft für jedes Element dieses Arrays die Methode print() auf, und gibt dann ein newline aus (damit jedes Objekt eine eigene Zeile bekommt). Arrays in Java beginnen mit dem Index 0, und die Anzahl der Elemente kann man mit .length ermitteln. Der höchste Index von a ist also a.length-1.
Beim Aufruf a[i].print() wird vom Array a das i. Element gelesen, eine Referenz auf ein Objekt einer Unterklasse von Obj. Dann wird das print() für die entsprechende Unterklasse aufgerufen, wobei die Referenz in der aufgerufenen Methodenimplementierung zu this wird.
public static void main(String [] args) {
Obj signed1 = new Signed(5); //5 new-signed constant signed1
Person person1 = new Person(1234567890L,"Jane Doe");
//1234567890 s" Jane Doe" new-person constant person1
signed1.print(); //signed1 .obj
Signed.print((Signed)signed1); //signed1 .signed
System.out.println(); //cr
Hier legen wir uns zunächst zwei Objekte an: Eines (signed1) vom Typ
Signed wird aber in einer variable vom Typ Obj gespeichert. Da Signed
ein Untertyp von Obj ist und damit überall dort vorkommen darf, wo Obj
vorkommen darf, geht das. Das andere Objekt (person1) hat den Typ
Person.
Dann geben wir signed1 auf zwei Arten aus: Als erstes durch den Aufruf der nichtstatischen abstrakten Methode print() der Klasse Obj für das Objekt signed1. Von dieser abstrakten Methode gibt es drei Implementierungen (für Signed, Person, und Student). Je nachdem, für welchen Typ von Objekt print aufgerufen wird, wird die entsprechende Implementierung ausgewählt und ausgeführt. Und zwar erfolgt diese Auswahl (dispatch) zur Laufzeit anhand des konkreten Typs zur Laufzeit (dynamic dispatch). Das sieht man hier daran, dass hier die print()-Implementierung von signed ausgeführt wird, obwohl der statische Typ der Variable signed1 Obj ist.
Die zweite Ausgabe erfolgt über die statische Methode print(Signed s) der Klasse Signed. Wenn wir uns in anderen Klassen auf statische Methoden beziehen, müssen wir die Klasse angeben, in der die statische Methode liegt; deswegen erfolgt der Aufruf hier mit Signed.print(...). Als Parameter übergeben wir signed1. Aber signed1 ist eine Variable vom Typ Obj. Daher können wir den Aufruf nicht einfach mit Signed.print(signed1) machen, denn wir haben keine statische Methode print(Obj) in Signed definiert. Damit wir Signed.print(Signed s) aufrufen können, müssen wir den Typ zuerst mit einem Cast in Signed umwandeln (konvertieren). Das geschieht mit "(Signed)signed1". Da das Ergebnis davon garantiert den Typ Signed (oder einen Untertyp davon) hat, und der Java-Compiler das jetzt auch weiß, kann man jetzt die statische Methode aufrufen.
Was bei dem Cast tatsächlich passiert, ist, dass der konkrete Typ des Objekts, auf das signed1 zeigt, überprüft wird, und wenn es nicht Signed (oder ein Untertyp von Signed) ist, wird das Programm abgebrochen. Wenn die Cast-Operation erfolgreich beendet wird, haben wir also garantiert ein Signed.
person1.print(); //person1 .obj
System.out.println(); //cr
System.out.println(); //cr
Die Ausgabe von person1 erfolgt über die abstrakte Methode print() von
Obj, genau wie oben die erste Ausgabe von signed1. Da das Objekt hier
eine Person ist, wird von den verschiedenen Implementierungen der
Methode die in der Klasse Person definierte ausgewählt und ausgeführt.
Obj a[]=new Obj[3]; //here 3 cells allot constant a
a[0] = signed1; //signed1 a 0 cells + !
a[1] = person1; //person1 a 1 cells + !
a[2] = new Signed(9);//9 new-signed a 2 cells + !
printArray(a); //a 3 .objarray
System.out.println();//cr
Hier legen wir ein Array a mit drei Elementen an, und initialisieren
die Elemente mit signed1, person1, und einem weiteren Signed-Objekt.
Dann geben wir diese Elemente mit printArray(Obj a[]) aus. Je
nachdem, ob das Objekt ein Signed oder eine Person ist, wird dabei die
entsprechende Implementierung von print() aufgerufen. Das
funktioniert so nur mit der abstrakten Methode print() von Obj, nicht
mit den diversen statischen Methoden oder den final-Methoden, eben
weil die abstrakte Methode print() von Obj dynamischen dispatch
benutzt, und die statischen Methoden nicht; und die final-Methoden
wurden so geschrieben, dass dort kein dynamischer dispatch passiert.
Student student1=new Student(9876543210L,"John Smith",1499999);
//9876543210 s" John Smith" 1499999 new-student constant student1
Student.print(student1); //student1 .student
System.out.println(); //cr
Person.print(student1); //student1 .person
System.out.println(); //cr
student1.print(); //student1 .obj
System.out.println(); //cr
System.out.println(); //cr
a[2] = student1; //student1 a 2 cells + !
printArray(a); //a 3 .objarray
}
}
Hier legen wir ein Objekt vom Typ Student an, und drucken es auf
verschiedene Weise: zunächst mit der statischen Methode
Student.print(Stident s), dann mit der statischen Methode
Person.print(Person s). Der erste Aufruf gibt die Matrikelnummer mit
aus, der zweite nicht, denn die statisch Methode Person.print() macht
das nicht.
Als drittes wird die abstrakte Methode print() def Klasse Obj aufgerufen, die wiederum zur Laufzeit die Implementierung dieser Methode in der Klasse Student wählt, weil das Objekt diesen Typ hat. Diese Ausgabe zeigt uns also wieder die Metrikelnummer an.
Schliesslich ersetzen wir die Zahl in a[2] durch student1, und rufen wieder printArray(a) auf. Diesmal gibt uns printArray als dritten Wert unseren Studenten John Smith aus statt der Zahl 9.
Zusammenfassend, was sind die wichtigen Aspekte des obigen Beispiels?
Methoden haben einerseits eine Schnittstelle (auch Signatur genannt), über die sie aufgerufen werden, also der Teil vor den geschwungenen Klammern, andererseits eine Implementierung (der Teil in den geschwungenen Klammern).
Während bei statischen Methoden die Schnittstelle mit der Implementierung fest verbunden ist, ist das bei nicht-statischen Methoden anders: Da kann es mehrere Implementierungen für eine Schnittstelle geben. Welche davon verwendet wird, entscheidet sich beim Aufruf zur Laufzeit anhand der konkreten Klasse des Objekts links vom Punkt (dynamisches Binden, dynamic dispatch).
Diese Trennung von Schnittstelle und Implementierung kann man auch ganz explizit machen, indem man die Schnittstelle als abstrakte Methode definiert, und die Implementierungen extra. Das ist in unserem Beispiel bei der nicht-statischen Methode print() gemacht worden, während bei den nicht-statischen Methoden printSigned(), printPerson() und printStudent() keine separate abstrakte Methode definiert wurde.
Ein weiterer Aspekt, den man an diesem Beispiel sehen konnte, ist die Vererbung: Unterklassen erben Felder von Oberklassen, in unserem Beispiel erbt die Klasse Student die Felder svnum und name von der Oberklasse Person.
Auch Methodenschnittstellen werden von Unterklassen geerbt: In unserem Beispiel vererbt Obj die Methodenschnittstelle print() an Signed, Person, und Student; und Person vererbt die Methodenschnittstelle printPerson() an Student (man kann also z.B. student1.printPerson() aufrufen).
Schliesslich werden Methodenimplementierungen von Unterklassen
geerbt, wenn die Unterklasse keine eigene Implementierung der Methode
hat; wenn die Klasse eine eigene Implementierung hat, sagt man auch,
dass die Unterklasse die Methode überschreibt (override). In unserem
Beispiel haben Signed, Person und Student jeweils eigene
Implementierungen von print(), sodass hier keine Vererbung sichtbar
wird. Dagegen erbt die Klasse Student die Implementierung von
printPerson() von der Klasse Person; das final bei der
Definition von printPerson() in Person sorgt auch dafür, dass die
Methode in Unterklassen nicht anders implementiert werden kann.
Der Name "Unterklasse" legt nahe, dass Unterklassen weniger können als Oberklassen. Das Gegenteil ist der Fall: Ein Objekt einer Unterklasse kann man überall einsetzen, wo ein Objekt der Oberklasse erwartet wird, Unterklassen müssen daher mindestens genauso viel können wie die Oberklassen. Oft können sie mehr.
Übung: Definieren Sie folgende statische Methode in der Klasse Person:
public static void print1(Person p) {
p.print();
}
Überlegen Sie sich, was passiert, wenn Sie in
main Person.print1(student1); schreiben, und warum.
Überprüfen Sie Ihre Theorie durch Compilieren und Laufenlassen des
Programms. Erklären Sie das Ergebnis.
Und wozu ist dynamic dispatch gut? Dynamic dispatch erlaubt es, an einer Stelle Objekte zu verwenden, die sich zwar von der Schnittstelle her gleich, aber ansonsten verschieden verhalten. Ein klassisches Beispiel ist ein Vektor-Grafik-Programm, wo Kreise, Rechtecke, Linienzüge, Bezierkurven, etc. alles einfach Grafik-Objekte sind, und wenn man so ein Objekt anzeigen will, ruft main einfach eine draw()-Methode dafür auf, und die Implementierungen dieser Methode sind für die verschiedenen Grafik-Objekte unterschiedlich, aber alle zeichnen das jeweilige Objekt.
abstract bei der Definition einer abstrakten Methode
in einem Interface weglassen. Ein syntaktischer Unterschied ist, dass
eine Klasse die Methoden eines Interfaces nicht
mit extends, sondern mit implements
übernimmt.
Eine Klasse kann in Java nur von maximal einer anderen Klasse direkt erben (extends), aber sie kann (stattdessen oder zusätzlich) noch beliebig viele Interfaces implementieren (implements). Interfaces können wiederum von einem oder mehreren anderen Interfaces erben (extends).
In unserem obigen Beispiel erfüllt die Klasse Obj sowohl die
Einschränkungen einer Klasse (erbt von maximal einer Klasse) als auch
die eines Interfaces (keine Felder, nur abstrakte Methoden, erbt
höchstens von Interfaces), und man kann diese Klasse daher ohne
Probleme in ein Interface umwandeln. Dazu muss nur das abstract
class Obj durch interface Obj ersetzt werden
und extends Obj durch implements Obj. Das
Ergebnis finden Sie in diesem
Verzeichnis.
Ein besserer (und den Java-Konventionen entsprechender) Name für dieses Interface wäre übrigens "Printable", da Objekte mit diesem Interface ausgegeben werden können.
Beim Programmieren stellt sich die Frage: Welche Klassen soll man jetzt als Untertypen welcher anderer Klassen im Programm vorsehen? Dabei werden häufig Fehler gemacht, die entweder gleich zu unnötig komplizierten Programmen führen oder später bei der Wartung Probleme machen.
Die Untertypbeziehung drückt eine Spezialisierung aus: Daher ist eine Faustregel, dass es oft sinnvoll ist, eine Untertypbeziehung zwischen zwei Typen zu haben, wenn die Konzepte, die sie modellieren, über eine "ist-ein"-Beziehung (engl: is-a) miteinander verbunden sind. Zum Beispiel: Ein Student "ist eine" Person.
Wenn man davon abweicht, führt das oft über kurz oder lang zu Problemen führen: Häufige Fehler sind zum Beispiel, eine "enthält"-Beziehung in der realen Welt zu einer Untertypbeziehung zu machen (z.B. Auto als Untertyp von Motor). Oder eine Entwicklung zur Grundlage von Untertypen zu machen: z.B. Vogel als Untertyp von Einzeller.
Selbst bei Ist-ein-Beziehungen muss man sich genau anschauen, ob Ersetzbarkeit gegeben ist. Z.B. ist ein Quadrat ein Rechteck. Aber wenn man für Rechteck eine Methode setGroesse(double x, double y) hat, wird man diese Methode wahrscheinlich nicht sinnvoll für Quadrate implementieren können. Wenn man also so eine Methode haben will, wird man Quadrat nicht als Untertyp von Rechteck definieren. Wenn man aber so eine Methode nicht hat, und für alle vorkommenden Methoden die Ersetzbarkeit gegeben ist, ist es durchaus sinnvoll, Quadrat als Untertyp von Rechteck zu definieren.
Mehr zu diesen Themen erfahren Sie in den LVAs objektorientierte Modellierung und objektorientierte Programmierung.
Wichtig ist insbesondere die Klasse Object, denn jede Klasse ohne Oberklasse hat diese Klasse implizit als Oberklasse, und jede andere Klasse hat Object dadurch indirekt als Oberklasse.
Die Klasse Object definiert eine Reihe von Methoden-Schnittstellen, die daher für Objekte aller Klassen aufgerufen werden können, u.a.:
Person p1 = new Person(1234567890L,"Jane Doe"); Person p2 = new Person(1234567890L,"Jane Doe");dann ergibt der Vergleich p1==p2 als Ergebnis false, weil "==" die Objektreferenzen vergleicht, also prüft, ob p1 auf das selbe Objekt zeigt wie p2 (und da p1 auf das Ergebnis eines new-Aufrufs zeigt und p2 auf das Ergebnis eines anderen, handelt es sich um verschiedene Objekte, die nur den gleichen Inhalt haben). Dagegen sollte p1.equals(p2) als Ergebnis true liefern; dazu müssen wir aber equals(Object) erst entsprechend definieren (Vorsicht, die in Object definierte Version vergleicht auf Identität):
public boolean equals(Object that) {
if (that != null && this.getClass() == that.getClass()) {
Person p = (Person) that;
return svnum == p.svnum && name.equals(p.name);
} else
return false;
}
Zunächst ist zu bemerken, dass diese Implementierung von
equals(Object) auch ein Object als Parameter nimmt. Das geht in Java
nicht anders (sonst waere es eine andere Methode), und es ist auch
sinnvoll, da wir dadurch beliebige Objekte auf Gleichheit vergleichen
können. Dann überprüfen wir, ob that nicht eine null-Referenz ist,
bevor wir prüfen, ob die Klasse von this identisch mit der Klasse von
that ist.
Da das eine Methode von Person ist, ist this ein Objekt (einer Unterklasse) von der Klasse Person. Und wenn der Vergleich der Klassen erfolgreich war (also im then-Zweig der if-Anweisung), wissen wir damit auch, dass die Klasse von that (eine Unterklasse von) Person ist, und können im nächsten Schritt that (von der statischen Klasse Object) zur Klasse Person umwandeln (casten) und einer Variable p vom Typ Person zuweisen. Da der dynamische Typ von that auf jeden Fall (eine Unterklasse von) Person ist, wissen wir auch, dass der cast keinen Fehler zur Laufzeit auslösen wird; wenn wir zuerst den Cast machen würden, und dann den Vergleich der Klassen, und wir übergeben z.B. ein Signed als Parameter that, würde der Cast einen Fehler zur Laufzeit produzieren, und zum Vergleich der Klassen würde es gar nicht kommen.
Die Reihenfolge des Vergleichs mit null und des Klassenvergleichs ist übrigens auch wichtig: Wir holen uns die Klasse von that nur, wenn wir wissen, dass that ungleich null ist.
Die Variable p vom Typ Person brauchen wir, damit wir auf die Personen-Felder von p/that zugreifen können und die dann mit den entsprechenden Feldern von this vergleichen können. Wir verleichen svnum mit p.svnum mit dem Operator ==, weil svnum ein Feld vom Typ long ist. Das ist einer der elementaren Typen von Java, diese vergleicht man mit == auf Gleichheit. Das Feld name ist dagegen vom Typ String, das ist ein Objekt-Typ und daher ist der richtige Vergleich auf Gleichheit für diesen Typ equals(Object). Allgemein gibt es in Java die Konvention, dass Objekt-Typen gross geschrieben werden (z.B. String), und elementare Typen klein (z.B. long); ein Array von einem Elementaren Typ ist allerdings auch ein Objekt-Typ.
Die beiden letzten Vergleiche liefern das Resultat, wenn der null-Vergleich und der Klassenvergleich erfolgreich waren. Sollte einer der beiden false ergeben haben (also wenn that gleich null ist oder eine andere Klasse als this hat), liefert unser equals(Object) false zurück.
Typische equals(Object)-Methoden für andere Klassen werden so ähnlich ausschauen.
Sie finden den Quellcode für dieses Beispiel hier und als Zip-Datei hier.
Übung: Von den vier Bedingungen im obigen equals(Object) dürfen nur die letzten beiden vertauscht werden, ohne einen Fehler einzuführen. Ändern Sie equals(Object) so, dass die erste Bedingung nach der zweiten geprüft wird, und in einem weiteren Versuch so, dass die zweite Bedingung nach der dritten geprüft wird, und fügen Sie in Main.java Testfälle ein, anhand derer man den Unterschied im Verhalten zwischen der neuen Variante und der ursprünglichen sehen kann.
Damit die Invariante "a.equals(b) => a.hashCode() == b.hashCode()" erhalten bleibt, muss man meist auch hashCode geeignet überschreiben. Idealerweise sollte auch, wenn die beiden Objekte ungleich sind, der Hash-Wert mit hoher Wahrscheinlichkeit verschieden sein. Wozu Hash-Werte gebraucht werden, erfahren Sie spätestens in Algorithmen und Datenstrukturen, wenn es um Hash-Tabellen geht; aber bei den Anwendungen von Hash-Werten geht es immer darum, dass man die obige Invariante umdreht: a.hashCode() != b.hashCode => !(a.equals(b)). Man hat damit also eine Abkürzung, um die Ungleichheit zu ermitteln, und kann sich damit einen aufwendigen equals-Vergleich mit vielen Objekten sparen.
Eine einfache und halbwegs brauchbare (wenn auch verbesserbare) Hash-Funktion für unsere Klasse Person ist:
public int hashCode() {
return ((int)svnum)+name.hashCode();
}
Alle Felder gehen in den Hash-Wert ein (bei svnum allerdings nur die
untersten 32 bits).
Das Feld svnum ist ein long, und muss in ein int konvertiert werden, damit wir es zu einem int addieren können und ein int herauskommt; dabei gehen die oberen 32bits verloren (bei svnum sind diese Bits aber fast alle 0, da eine österreichische Sozialversicherungsnummer nur 10 Stellen hat). Die Konversion erfolgt mit der selben Syntax wie beim Casten eines Objekt-Typs in einen spezialisierteren Objekt-Typ, und die Operation wird auch Cast genannt, aber was dabei passiert, ist doch recht verschieden:
Beim Cast eines Objekt-Typs wird an dem Objekt und der Referenz darauf nichts geaendert, sondern nur überprüft, ob das referenzierte Objekt tatsächlich den Typ hat, in den gecastet wird (oder einen Untertyp dieses Typs), und ggf. einen Fehler meldet.
Im Gegensatz dazu erfolgt beim Casten eines elementaren Typ meist eine Änderung: Bits werden hinzugefügt oder weggeworfen (bei Konversion zwischen verschiedenen ganzzahligen Typen), oder die Repräsentation ist überhaupt deutlich anders (z.B. bei Konversionen zwischen ganzzahligen und Gleitkomma-Typen).
In Java gibt es zu den elementaren Typen auch entsprechende
Objekt-Typen, z.B. Objekt-Typ Long zum elementaren Typ Long und
Objekt-Typ Integer zum elementaren Typ int. Wenn wir svnum als Long
und nicht als long definiert hätten, hätten wir die Konversion nicht
mit einem Cast auf Integer oder int machen können, sondern
mit svnum.intValue() (für int)
bzw. Integer.valueOf(svnum.intValue()) (für Integer).
Übung: Welche Hash-Werte erhalten Sie für p1 und p2? Welche erhalten Sie, wenn Sie hashCode() nicht für Person implementieren? Unter welchen Umständen ist die Invariante zwischen equals(Object) und hashCode() erfüllt?
Quellcode für folgendes in diesem Verzeichnis.
Es wäre recht praktisch, eine allgemeine Liste für Java implementieren zu können, mit beliebigen Objekt-Typen als Nutzlast. Fangen wir mit einer einfachen Listenknoten-Klasse an:
public class OListNode {
public OListNode next;
public Object val;
...
}
Damit kann man zwar mit den val-Feldern alles machen, was man mit
Object-Objekten so machen kann, z.B. die Methode equals(Object)
aufrufen, aber nicht so ohne weiteres mehr. Wenn wir z.B. wissen,
dass alle Nutzlasten in der Liste Objekte eines Untertyps von Obj
(unserem Typ mit der print()-Methode) sind, möchten wir vielleicht
alle Elemente der Liste mit print() ausgeben. Das geht aber nicht so
ohne weiteres, denn val ist vom Typ Object, und dieser Typ hat keine
Methode print().
Man kann das Problem aber lösen, indem man val auf den Typ Obj castet:
public static void printList(OListNode l) {
for (; l!=null; l=l.next) {
((Obj)(l.val)).print();
System.out.println();
}
}
Das wird vom Java-Compiler verarbeitet, und man kann Listen mi
Untertypen von Obj als Nutzlasten bauen, und dieses
printList(OListNode) wird so eine Liste klaglos ausgeben.
Allerdings kann man auch z.B. ein String als Nutzlast verwenden, und kann dann printList(OListNode) mit dieser Liste als Parameter aufrufen; der Compiler beschwert sich darüber nicht, allerdings gibt das einen Fehler zur Laufzeit: der Cast auf Obj entdeckt, dass val auf ein String zeigt, und weil das kein Untertyp von Obj ist, meldet der Cast einen Fehler. Das ist dynamische Typüberprüfung.
Eventuell möchten wir aber lieber die Möglichkeit haben, von vornherein nur Untertypen von Obj als Nutzlast zu verwenden, sodass solche Typfehler zur Laufzeit nicht auftreten. Das geht mit Typ-Parametern in Java:
public class ListNode<A> {
public ListNode<A> next;
public A val;
...
}
Die Klasse ListNode hat den Typparameter A, für den ein beliebiger
konkreter Typ eingesetzt werden kann, z.B. Obj. In der
Klassendefinition kommt A dort vor, wo bei OListNode Object vorkam,
und fast überall ListNode<A>, wo in OListNode OListNode vorkam
(nur beim Konstruktornamen muss man den Typparameter weglassen).
Bei der Verwendung von ListNode<A> setzt man einfach den gewünschten Typ statt A ein:
public static void printList(ListNode<Obj> l) {
for (; l!=null; l=l.next) {
l.val.print();
System.out.println();
}
}
Hier braucht man keinen Cast auf Obj, weil val ja vom Typ Obj ist.
Und wenn man versuchen würde, ein Objekt mit einem unpassenden Typ als
Nutzlast zu verwenden, meldet schon der Compiler einen Fehler,
z.B. wenn man in Main folgendes versucht:
k=new ListNode<Obj>(k,"acde");Der Stoff für den dritten Test geht bis hierher.

Da gerichtete Bäume praktisch immer so gezeichnet werden, dass die Kanten alle in eine Richtung zeigen (im obigen Beispiel von oben nach unten), zeichnet man die Kanten meistens nicht als Pfeile, sondern als einfache Linien; es handelt sich trotzdem um einen gerichteten Graphen.
Beispiele für Bäume ausserhalb der Informatk sind natürlich botanische Bäume (wobei sowohl der Teil vom Stamm aufwärts als auch der Teil vom Stamm abwärts (das Wurzelsystem) Bäume im Sinne der Graphentheorie sind), Stammbäume (wobei die Nachkommen einer Person ebenso einen Baum bilden wie die Vorfahren einer Person), Organigramme, Flusssysteme, und das K.O.-System für Turniere.
Beispiele in der Informatik ist der die Klassenhierarchie (nicht die Interface-Hierarchie) in Java und der (dynamische) Aufrufbaum: Ausgehend von der main-Methode werden andere Methoden aufgerufen, die wiederum andere Methoden aufrufen; wenn man jeweils den Aufrufer und die Aufgerufene Methode über eine Kante verbindet, und dabei für verschiedene Aufrufe derselben Methode eigene Knoten anglegt, erhält man den Aufrufbaum. Für hist.fs wäre das (wenn man nur die dort definierten Wörter darstellt):
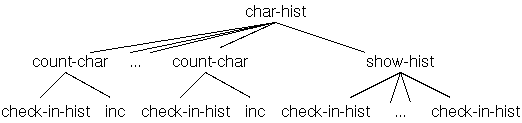
Als Datenstrukturen kommen recht häufig binäre Bäume auf, also Bäume, bei denen jeder Knoten höchstens zwei Nachfolgeknoten hat.
Im folgenden werden wir uns mit dem binären Suchbaum befassen. Dabei ist die Nutzlast jedes Baumknotens mit der jedes anderen vergleichbar, und diese bilden eine totale Ordnung (z.B. Zahlen, oder lexikographische Ordnung von Strings). Betrachten wir einen beliebigen Knoten n: Dabei ist die Nutzlast von n größer als die Nutzlasten der Knoten, die über den linken Nachfolger erreichbar sind, und kleiner als die Nutzlasten der Knoten, die über den rechten Nachfolger erreichbar sind. Wenn das für alle Knoten im Baum gilt, haben wir einen binären Suchbaum.
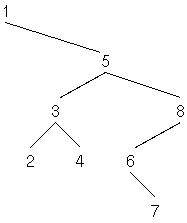
Im folgenden definieren wir eine Klasse Tree für den binären Suchbaum. Im Interesse der Einfachkeit vewrwenden wir einfach int als Nutzlast und vergleichen das mit <. Eine allgemeinere Version würde auf das Interface Comparable aufbauen. Das Kernstück der Implementierung ist die Klasse Node:
class Node {
int val;
Node left, right;
Node(int v) {
val=v;
left=null;
right=null;
}
Jeder Baumknoten hat eine Nutzlast val und einen linken (left) und
rechten (right) Nachfolgeknoten (gelegentlich spricht man auch vom
Vaterknoten und dem linken und dem rechten Kind). Die Referenzen auf
die Nachfolgeknoten werden mit null initialisiert, ein Knoten wird
also zunächst als Blatt erstellt.
static boolean contains(Node n, int v) {
while (n!=null) {
if (v==n.val)
return true;
if (v<n.val)
n = n.left;
else
n = n.right;
}
return false;
}
Die Methode contains überprüft, ob v im Baum enthalten ist. Dazu vergleicht sie nicht mit jedem Knoten, sondern nutzt die Eigenschaften des Suchbaums aus, um nur wenige Knoten anschauen zu müssen.
Zunächst wird überprüft, ob n tatsächlich ein Knoten ist; wenn es null ist, haben wir v nicht gefunden und liefern false zurück.
Als nächstes prüfen wir, ob n der Knoten mit dem Wert gleich v ist. Wenn ja, dann ist v im Baum enthalten und wir liefern true zurueck.
Wenn beides nicht zutrifft, müssen wir im Baum weitersuchen. Aufgrund der Suchbaum-Eigenschaft müssen wir aber nicht beide Unterbäume durchsuchen, sondern nur einen: Wenn v<n.val, den linken, sonst den rechten.
static Node insert(Node n, int v) {
if (n==null)
return new Node(v);
if (v==n.val)
return n;
if (v<n.val)
n.left=insert(n.left, v);
else
n.right=insert(n.right, v);
return n;
}
Das Einfügen eines neuen Wertes in den Baum veräuft im Prinzip
ähnlich. Allerdings muss man hier eventuell einen neuen Knoten an den
Baum anfügen. Wenn Java Referenzen auf Speicherstellen hätte, würde
der Code tatsächlich dem Code von contains recht ähnlich sehen (siehe
member? und search für verkettete Listen in Forth). Der Trick mit dem
prehead, den wir in Java bei verketteten Listen verwendet haben,
funktioniert auch nicht so einfach, da man ja entweder left oder right
verändern muss.
Was wir hier machen, ist, dass insert einfach den (Unter-)Baum mit dem neuen Knoten zurückgibt, und der dann in das entsprechende Feld gespeichert wird. Wenn n==null, ist das besonders einfach: insert gibt einfach einen neuen Blattknoten zurück.
Als weiteren Sonderfall betrachten wir den Fall, wenn der Wert schon im Baum vorhanden ist; dann fügen wir nichts ein, sondern geben einfach n unverändert zurück. Diese Implementierung des Baumes merkt sich also nicht, wenn der gleiche Wert mehrfach eingefügt wurde.
Wenn beides nicht zutrifft, müssen wir v in einen Unterbaum einfügen. Wenn v<n.val, in den linken, sonst in den rechten. Das Einfügen machen wir, indem wir insert mit den entsprechenden Parametern aufrufen. Das Ergebnis des Aufrufs speichern wir in das entsprechende Feld. In den meisten Fällen bleibt der Inhalt des Feldes dabei gleich (immer noch eine Referenz auf den entsprechenden Nachfolgeknoten), aber wenn das Feld ursprünglich null enthielt, dann wird es durch die Referenz auf einen Blattknoten überschrieben.
Den Aufruf einer Methode durch sich selbst nennt man Rekursion. Er funktioniert eigentlich wie jeder andere Aufruf auch, und man betrachtet ihn beim Programmieren am besten auch einfach abstrakt als einen Aufruf, der etwas bestimmtes erledigen soll. Ein Unterschied: Damit es nicht zur Endlosrekursion kommt, muss man genau wie bei Schleifen darauf schauen, dass man sich bei jedem rekursiven Aufruf der Abbruchbedingung (hier: n==null) nähert. Ein weiterer wichtiger Aspekt bei rekursiven Aufrufen ist, dass jeder Aufruf neue Exemplare (Instanzen) der lokalen Variablen und Parameter (hier n und v) erhält, sodass nach der Rückkehr vom rekursiven Aufruf die gleichen Werte in diesen Variablen sind wie davor.
"insert" ist übrigens der übliche Name für solche Einfügeoperationen bei Leuten, die sich mit Algorithmen und Datenstrukturen befassen. In Java-Datenstrukturen heisst diese Operation aber üblicherweise "add".
static String toString(Node n) {
if (n==null)
return "";
return toString(n.left)+" "+n.val+" "+toString(n.right);
}
Die Methode toString soll einen String zurückliefern, der die Elemente
des Baumes sortiert enthaelt. Wenn n==null, dann liefert es einen
Leerstring zurück. Der andere Fall ist interessanter: Da wird der
String erzeugt, indem der sortierte String des linken Unterbaums der
String für n.val und der sortierte String für den rechten Unterbaum in
dieser Reihenfolge zusammengefügt werden. Da n.val größer als alle
Elemente des linken TUnterbaums und kleiner als alle Elemente des
rechten Unterbaums ist, ist n.val im String an genau der richtigen
Stelle, und da die Strings der beiden Unterbäume beide sortiert sind,
ist auch das Resultat der Stringverkettung ein sortierter String und
kann einfach so zurückgegeben werden.
Diese drei Methoden sind alle static, und die Referenz auf den Knoten, der bearbeitet wird, wird als Parameter übergeben. Das erlaubt es, auch null zu übergeben, sodass die Abfrage auf null in der Methode an einer Stelle erfolgen kann.
Wenn man stattdessen nicht-statische Methoden schreiben würde, die den Referenz auf den Knoten als this übergeben bekommen, dann dürfte man diese Methoden nicht mit null aufrufen und mÜsste bei jedem Aufruf eine Sonderbehandlung für null einbauen. Zusammen mit den Aufrufen in tree sind das für insert und toString jeweils drei Aufrufe.
Wenn man toString(x) aufruft, wobei x auf den Wurzelknoten des oben gezeigten Suchbaumes zeigt, dann ergibt sich folgender Aufrufbaum (rechts):
In dieser Grafik werden die Kanten doppelt gezeigt: Die Aufrufe in schwarz, die Rückkehr von den Aufrufen in rot; bei der Rückkehr wird auch der zurückgegebene String angezeigt (in rot). Das übergebene argument ist ja immer ein Knoten des Baumes, oder null; bei einem Knoten zeigt die Grafik durch einen türkisen Pfeil an, um welchen Knoten es sich handelt.
Die Methode toString(Node) besucht jeden einzelnen Knoten über einen Aufruf, daher spiegelt der Aufbau des Aufrufgraphen den Aufbau des Baums wider. Zusätzlich hat der Aufrufgraph noch Kanten und Knoten für die Felder im Baum, die null enthalten.
Die nächste Graphik zeigt den Aufruf"baum" von insert(x,9), wobei x auf den Wurzelknoten des oben gezeigten Suchbaumes zeigt.
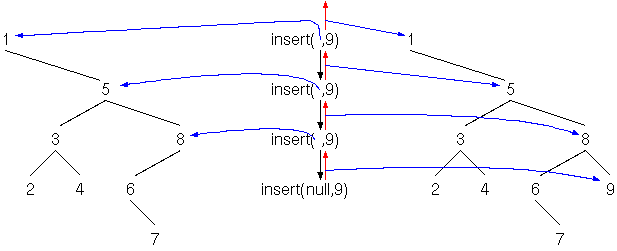
Wieder werden sowohl der Aufruf (schwarz) als auch die Rückkehr (rot) gezeigt. Links sieht man den ursprünglichen Baum, rechts das Ergebnis der Einfügeoperation. Wieder werden die Node-Argumente durch türkise Pfeile symbolisiert. Diesmal werden auch Knoten zurückgegeben, diese werden ebenfalls durch türkise pPfeile symbolisiert.
Insbesondere liefert insert(null,9) einen neugeschaffenen Knoten mit val=9 zurück, der dann in den existierenden Baum eingehängt wird.
Diesmal wandert die Rekursion nur jeweils in eine Richtung den Baum hinunter, dementsprechend hat jeder Knoten im Aufrufbaum maximal einen Nachfolger. Wieder gibt es für den null-Fall zusätzliche Aufrufe, diesmal nur einen.
Unsere Node-Klasse kann schon recht viel, aber normalerweise versteckt man die hinter einer weiteren Klasse, die dann eine für Java idiomatischere Schnittstelle zur Verfügung stellt: nicht-statische Methoden, besonders für toString(), wo ja so eine Methodenschnittstelle von Object herkommt:
public class Tree {
Node root=null;
boolean contains(int v) {
return Node.contains(root,v);
}
void insert(int v) {
root=Node.insert(root,v);
}
public String toString() {
return Node.toString(root);
}
}
Mit dieser Klasse können wir auch für einen leeren Baum ein
Tree-Objekt haben, und dafür dann nicht-statische Methoden wie zum
Beispiel t.toString() aufrufen; wenn wir uns nur auf Node beschränken
würden, müssten wir leere Bäume durch null repräsentieren und können
dafür nicht t.toString() aufrufen. Die Methode insert(int) braucht
nichts zurückliefern; verändert wird ggf. das Feld root.
Und hier einige Aufrufe der Methoden von Tree:
public class Main {
public static void main(String [] args) {
Tree t=new Tree();
System.out.println(t.contains(6));
System.out.println(t.toString());
t.insert(1);
t.insert(5);
t.insert(3);
t.insert(8);
System.out.println(t.contains(6));
t.insert(2);
t.insert(4);
t.insert(6);
t.insert(7);
System.out.println(t.contains(6));
System.out.println(t.toString());
}
}
Die insert-Aufrufe bauen den oben gezeigten Suchbaum auf. Man beachte
insbesondere, dass beim ersten Aufruf von insert in einen leeren Baum
eingefügt wird, und davor contains(int) und toString() mit dem leeren
Baum aufgerufen werden.
Allerdings wird gerade im Bereich der Verarbeitungsgeschwindigkeit (Performance) viel Unsinn verbreitet und programmiert. Wobei mancher Unsinn durchaus eine sinnige Grundlage hat, und nur in der Anwendung unsinnig ist; wenn man zum Beispiel in einem Programmteil, der nicht nennenswert zur Laufzeit beiträgt, eine komplizierte Optimierung einbaut, hat man bezüglich der Verarbeitungsgeschwindigkeit nichts gewonnen, aber den Entwicklungsaufwand, Wartungsaufwand und eventuell die Entwicklungszeit erhöht und mit höherer Wahrscheinlichkeit Fehler eingebaut.
Einige Sprüche zu dem Thema spiegeln das wieder:
"Premature optimization is the root of all evil." Donald Knuth
"The First Rule of Program Optimization: Don't do it. The Second Rule of Program Optimization (for experts only!): Don't do it yet." Michael A. Jackson
Das andere Extrem wiederum ist, wenig oder gar keinen Gedanken an Effizienz zu verschwenden, denn "die Maschinen sind heutzutage ohnehin schnell genug". Als Ergebnis höre ich immer wieder von Projekten, die scheitern, weil die Performance nicht stimmt. Den richtigen Mittelweg zwischen diesen beiden Extremen zu finden, ist eine Kunst, für die allerdings eine gute Grundlage an Wissen über Programmierung und Algorithmen und Datenstrukturen nötig ist.
Aber einige Grundregeln werde ich im folgenden vermitteln, und weiteres Wissen dazu erhalten Sie in "Algorithmen und Datenstrukturen", und in den Wahllehrveranstaltungen "Effiziente Programme" und "Effiziente Algorithmen".
Die O(...)-Notation kommt aus der Mathematik und betrachtet abstrakt Verhalten von Funktionen bei grossen Operanden und vernachlässigt dabei konstante Faktoren und untergeordneter Terme. So ist zum Beispiel die Funktion 3n2+1000000n+1020 bei genügend großen n immer noch kleiner als 4n2, und für ein noch größeres n kleiner als 3.5n2; der konstante Faktor 4 bzw. 3.5 fällt bei der O(...)-Notation auch unter den Tisch , also fasst man diese drei Funktionen unter O(n2) zusammen.
Wichtig ist das vor allem, um abschätzen zu können, ob ein Algroithmus auch für große Problemgrößen schnell genug ist. In der Informatik haben wir es öfters mit Algorithmen der Komplexität O(1) (konstant), O(ln n) (logarithmisch), O(n) (linear), O(n ln n), O(n2) (quadratisch), O(2n (exponentiell) zu tun. Betrachten wir einmal konkrete Funktionen dieser abstrakten Klassen; wir verwenden kleine konstanten Faktoren, da eine einzelne Operationen im Computer sehr schnell ist. Gerade diese kleinen konstanten Faktoren machen aber Messungen bei kleinen Problemgrößen oft trügerisch:
Klasse O(1) O(ln n) O(n) O(n2) O(2n) Funktion 1 ns ld n ns n ns n2 2n ns n=10 1ns 3ns 10ns 100ns 1024ns n=20 1ns 4ns 20ns 400ns 1ms n=50 1ns 6ns 50ns 2500ns 13d n=100 1ns 7ns 100ns 0.01ms 4*1013a n=1000 1ns 10ns 1000ns 1ms n=106 1ns 20ns 1ms 17m n=109 1ns 30ns 1s 32a n=1012 1ns 40ns 17mBei Algorithmen höherer Komplexität sind die maximalen praktisch lösbaren Problemgrößen recht klein. Wenn man die Wahl hat, wird man einen Algorithmus bzw. eine Datenstruktur niedriger Komplexitätsstufe wählen, oder besser, sein Programm so gestalten, dass man bei Bedarf so einen Algorithmus bzw. so eine Datenstruktur einsetzen kann.
In dem Zusammenhang ist auch noch zu erwähnen, dass manche Probleme grundsätzlich so schwer sind, dass sie sich wahrscheinlich nur mit exponentiellen Algorithmen lösen lassen (NP-vollständige Probleme); es gibt sogar Probleme, die nicht einmal sicher in endlicher Zeit gelöst werden können (unentscheidbare Probleme, z.B. das Halteproblem).
Diese Resultate aus der theoretischen Informatik sind zwar wichtig, aber kein Grund, gleich aufzugeben. Viele NP-vollständige Probleme sind Optimierungsprobleme, bei denen man mit Heuristiken in vertretbarer Zeit eine sehr gute, wenn auch nicht garantiert optimale Lösung finden kann. Bei anderen Problemen ist es oft immer noch interessant, für die Probleme, die in akzeptabler Zeit gelöst werden können, eine Lösung zu bekommen; für die anderen wird dann ein anderer Weg gewählt, zum Beispiel indem man das Problem weiter vereinfacht, auch wenn man eigentlich lieber das ursprüngliche Problem gelöst hätte.
Wie ermitteln wir jetzt die algorithmische Komplexität? Dazu berechnet man, wie oft ein bestimmter Programmschritt vorkommt. Von den in Frage kommenden Programmschritten nimmt man den, der am öftesten ausgeführt wird; normalerweise gibt es da mehrere Kandidaten, die alle dieselbe Komplexität ergeben. Betrachten wir das für die einzelnen Algorithmen auf unserem Baum:
static boolean contains(Node n, int v) {
while (n!=null) {
if (v==n.val)
return true;
if (v<n.val)
n = n.left;
else
n = n.right;
}
return false;
}
Bei contains wählen wir einfach die Anzahl der Iterationen der
Schleife als Masszahl. Für jede Kante, die auf der Scuhe nach dem
Element durchlaufen wird, wird eine weitere Iteration der Schleife
durchlaufen, wir durchlaufen aber von jedem Knoten ausgehend nur eine
Kante. Ein Unsicherheitsfaktor ist dabei die Struktur des Baumes, ein
anderer, ob das gesuchte Element vorhanden ist.
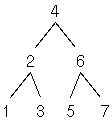
Bei einem perfekt balancierten Baum, in dem jeder innere Knoten zwei Kinder hat, ist in der ersten Ebene 1 Knoten, in der zweiten 2, in der dritten 4, in der n-ten 2n-1 Knoten, insgesamt bei n Ebenen 2n-1 Knoten. Wenn das gesuchte Element im Baum ist, hat man eine Wahrscheinlichkein von 1/(2n-1), das Element in der ersten Ebene zu finden, von 2/(2n-1), es in der zweiten Ebene zu finden, usw. In Durchschnitt wird man es in der vorletzten Ebene finden, also O(n-1) (=O(n)), wobei n hier die Anzahl der Ebenen ist; wenn man von der Anzahl der Elemente e ausgeht, kommt man auf O(ld(e+1))=O(ln e). Wenn das Element nicht gefunden wird, muss man eben bis zur letzten Ebene durchsuchen, dann kommt man allerdings in der O(...)-Notation ebenfalls auf O(ln e).
Wenn die Elemente einfach in völlig zufälliger Reihenfolge in den Baum eingefügt werden, ist der Baum am Ende nicht perfekt balanciert, aber die Tiefe ist (im Durchschnitt) nur um einen konstanten Faktor schlechter. Daher gilt auch in diesem Fall, dass contains O(ln e) Schritte braucht (allerdings mit einem schlechteren konstanten Faktor).
Wenn der Baum allerdings deutlich schlechter balanciert ist (im Extremfall so degeneriert, dass ein Baum mit n Elementen n Ebenen hat), ist die Komplexität von contains allerdings höher, bis zo O(n).
insert funktioniert sehr ähnlich wie contains (nur wird nach der Suche noch eingefügt), und die algorithmische Komplexität ist dieselbe.
Die Anzahl der Aufrufe in toString ist also linear in der Anzahl der Elemente des Baums (O(e)) (unabhängig von der Struktur des Baums). Allerdings sind die Operationen in einem Aufruf von toString() nicht unbedingt konstante Kosten: die Kosten der Stringverkettung + wird wohl linear mit der Länge des Ergebnisstrings steigen. Dadurch kommt man für toString() auf höhere Kosten als O(e).
Um die theoretische algorithmische Komplexität in Beziehung zur Realität zu setzen, vergleichen wir im Folgenden die Laufzeiten von insert, contains, und toString vom Suchbaum mit denen einer Implementierung einer sortierten verketteten Liste (wo insert und contains O(e) sind). Dazu verwenden wir Benchmark-Programme, die Bäume aus (pseudo-)zufälligen Werten aufbaut und solche Werte im Baum sucht. Der insert-Benchmark führt ca. 8 Millionen inserts aus (und baut dabei viele Bäume der entsprechenden Größe auf), der contains-Benchmark baut einen Baum mit n Knoten (mit n inserts) auf und macht dann ca. 8 Millionen contains, der toString-Benchmark baut so einen Baum auf und macht dann 20 toString()s.
Suchbaum sortierte Liste
n insert contains toString insert contains toString
2 0.82s 0.65s 0.16s 0.75s 0.54s 0.17s
4 0.90s 0.81s 0.16s 0.75s 0.62s 0.15s
8 1.06s 0.82s 0.17s 0.81s 0.70s 0.18s
16 1.16s 0.88s 0.18s 0.86s 0.72s 0.18s
32 1.30s 0.96s 0.16s 0.98s 0.92s 0.17s
64 1.49s 1.11s 0.19s 1.17s 1.19s 0.20s
128 1.68s 1.35s 0.20s 1.54s 1.70s 0.24s
256 1.82s 1.44s 0.25s 2.26s 2.82s 0.30s
512 1.98s 1.59s 0.29s 4.06s 4.88s 0.47s
1024 2.16s 1.81s 0.39s 7.42s 8.73s 0.65s
2048 2.39s 2.05s 0.50s 15.98s 39.56s 1.10s
4096 2.68s 2.36s 0.60s 77.39s 169.05s 2.62s
Die Werte wachsen hier nicht überall so wie erwartet; zum Beispiel
würde man bei O(n)-Algorithmen (insert und contains von der sortierten
Liste) erwarten, dass bei größeren n die Zeit um den Faktor zwei
ansteigt, wenn n um den Faktor 2 ansteigt; die Abweichungen kommen
vielleicht von von Caches, JIT-Compilern, oder Garbage Collection.
Aber jedenfalls sind insert und contains vom Suchbaum bei größeren n
deutlich schneller als die entsprechenden Operationen bei einer
sortierten Liste. Interessanterweise ist sogar toString beim Suchbaum
schneller, vermutlich weil im Suchbaum die Stringverkettungen im
Durchschnitt mit kürzeren Strings gemacht werden.
Code (die Benchmark-Programme müssen für die andere Datenstruktur geändert werden).
Zweck:
Beispiel: counter (Variationen siehe Kommentar).